DIFFERENT FACETS OF INEQUALITY
There is much discussion ofinequality but there is also much confusion, as the term means different things to different people. Inequality arises in many spheres of human activity.
People have unequal political power. People may be unequal before the law. In these two volumes, we are concerned with one particular dimension: economic inequality.Even limiting attention to economic inequality, there are many interpretations and careful distinctions have to be drawn. It is convenient to first make a distinction between monetary and nonmonetary inequality. The former, refers to standard dollar-valued magnitudes associated with the economic activity of an individual or a household (earnings, income, consumption expenditures, and wealth). Nonmonetary inequality, also referred to here as “beyond income” inequality, addresses broader dimensions of economic life such as well-being or capability.
2.1 Monetary Inequality
Restricting inequality to monetary magnitudes does not prevent confusion. In the media, one often hears statements like “the wealth of the richest x billionaires would feed all the poor in a particular country.” But this confuses wealth, which is a stock, with income or consumption, which are flows. Flows have to be specified as occurring over a certain period, so that the figures for overall inequality in Figure 1a relate to annual income. Wealth, shown in Figure 1d, is in contrast measured at a point in time. If billionaires gave away all their wealth this year to feed poor families, then they would not appear in the Forbes list next year. If, on the other hand, they gave away the income from their wealth, then the gift would be smaller but they could go on doing it year after year.
There is often confusion between income and earnings. Articles in the academic literature may contain in their titles the words “distribution of income,” but they are often actually about the distribution of earnings, and earnings are only part of income.
Often too they look only at those in work, and tell nothing about the inequality of income among pensioners or the unemployed. The distinction between earnings and income is made clearly in Chapter 18 by Wiemer Salverda and Daniele Checchi. They observe that there appear to be two largely separate literatures, one concerned with earnings and one with income distribution; their chapter plays an important role in bridging this divide. As they note, it is a question not only of “inequality of what?” but also of “inequality among whom?” Earnings are typically considered on an individual basis. The earnings at the top decile (the person 10% from the top) shown in Figure 1c are those of individual workers, whereas the income measured by overall inequality is the total income of the household.A person may have zero earnings, and no other income, but live in a household which is comfortably off. Such a situation does of course raise interesting questions—both for the analysis of inequality and in real life. What is the distribution within the household? The curve highlighted in the upper part of Figure 1a refers to the inequality of equivalized household income, which imputes to each member the total income of the household divided by the size of the household corrected by a factor that takes into account economies of scale as well as age-dependent needs. This assumes that all household members enjoy the same well-being. The topic of intrahousehold inequality is addressed in Chapter 16 by Pierre-Andre Chiappori and Costas Meghir. As they stress, both the level of inequality and the trend over time may be quite different. This issue is particularly relevant to gender inequality, which is the subject of Chapter 12 by Dominique Meurs and Sophie Ponthieux.
Overall inequality is summarized in Figure 1 in terms of the Gini coefficient, and this is the statistic most commonly published by statistical agencies. The typical explanation of the coefficient is geometric: the Gini coefficient is equal to the ratio of the area between the Lorenz curve and the diagonal to the area of the whole triangle under the diagonal.
As illustrated in Figure 2, the Lorenz curve shows the proportion of income received by the bottom F percent as a function of F. Where the Lorenz curve is close to the diagonal (curve A in Figure 2), the Gini coefficient is small; where the Lorenz curve hugs the horizontal axis (curve B), the coefficient is closer to 1. If we are comparing two Lorenz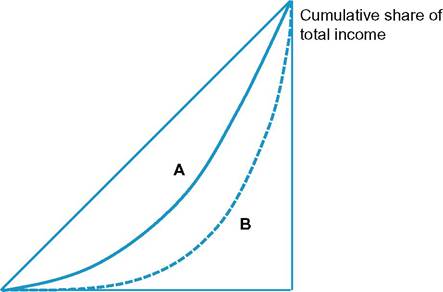
Cumulative share of total population
Figure 2 Lorenz curves. Note: The Gini coefficient of the distribution A is equal to the ratio to the whole triangle of the area between the curve A and the diagonal.
curves that do not cross, as with A and B, then one (in this case, A) definitely has a lower Gini coefficient. In this case we have Lorenz dominance, and A scores better than B on a wide variety of inequality measures (Atkinson, 1970). The converse is not true. The fact that the Gini coefficient is lower does not imply that the Lorenz curve is everywhere higher: the curves may intersect. The Gini coefficient can also be described in terms of the mean difference. A Gini coefficient of G percent means that, if we take any two households from the population at random, the expected difference is 2G percent times the mean. So that a rise in the Gini coefficient from 30% to 40% implies that the expected difference has gone up from 60% to 80% of the mean. Another useful way of thinking, suggested by Sen (1976), is in terms of “distributionally adjusted” national income, which with the Gini coefficient is (100G) percent of national income. So that a rise in the Gini coefficient from 30% to 40% is equivalent to reducing national income by 14% (i.e., (100 — 40)/(100 — 30) = 6/7 of its previous value).
We may be interested, not just in overall inequality, but also in the top and bottom of the distribution. The top income shares, for which we have the longest run of data in Figure 1, stretching back in the United States to 1913, show the share of total gross income (i.e., before deducting the taxes paid) accruing to the top 0.1%.
Figures like these, or the share of the top 1%, have appeared on the placards at demonstrations, such as those of the Occupy Movement. At the bottom of the scale, the poverty figures record the number of people living below the official line, which in the United States dates back to the War on Poverty launched by PresidentJohnson in the 1960s. The evolution of top income shares receives particular attention in Chapter 7 by Jesper Roine and Daniel Waldenstrom on long-run trends. Chapter 8 by Salvatore Morelli, Timothy Smeeding, and Jeffrey Thompson discusses whether top shares are proxies for overall inequality. This chapter and Chapter 9 by Facundo Alvaredo and Leonardo Gasparini on the post-1970 trends provide evidence about both top and bottom of the scale. In a different sense, the concentration of people at the top and at the bottom of the distribution, or by complement the size of the “middle class,” leads to the concept of “polarization,” another concept, discussed in Chapter 5 by Jean-Yves Duclos and Andre-Marie Taptue. There are still many other ways to measure inequality than the Gini or percentage shares, whether it refers to income, earnings, consumption, or wealth. Likewise, there are many ways of expressing social welfare as a combination of some inequality measure and the mean income of a population. These were extensively reviewed in the first volume of this Handbook.The panels in Figure 1 present therefore quite a rich picture of inequality in the United States over the past 100 years. But there is much that is missing. Figure 1 is a sequence of snapshots, rather than a movie. The top 0.1% in the United States in 1913 were those in the top group in that particular year; some of these people would have fallen out of the group by 1914. The statistics presented in Figure 1 tell us nothing about such mobility, which is the subject of Chapter 10 by MarkusJantti and Stephen Jenkins. As they explain, there are two aspects. First, there is the subject of how an individual’s income changes from one year to the next during their lifetime; on the other hand, there is the subject of income change between generations of parents and children.
Such a distinction between intragenerational and intergenerational income mobility reflects the division in the existing literature, but one of the features of their chapter is that it draws out the elements of the measurement of income mobility that are common to both topics. They also raise the measurement issues associated with the inherently multidimensioned information about incomes over time; many of these issues are the counterpart of those that arise when one considers multidimensionality at a point in time (see in the next section).Figure 1 shows evidence about the distribution of income within one country, but inequality is local and global as well as national. To begin with, money income has different purchasing power depending on local prices, and geographical variation can have a significant impact, as has been shown in the work of Moretti (2013) on the college wage premium in the United States. Spatial inequality is highlighted by Ravi Kanbur in Chapter 20. As he notes, “the spatial dimension of inequality is a key concern in the policy discourse, because it intersects with and interacts with disparities between subnational entities and jurisdictions. These entities sometimes have defined ethnic or linguistic characteristics, and in Federal structures have constitutional identities which naturally lead to a subnational perspective on national inequality.” Inequality equally intersects with concerns about globalization, which is the main subject of Chapter 20. The world distribution of income is the subject of Chapter 11 by Sudhir Anand and Paul Segal—see also Bourguignon (2013).
We have referred above to the important topic of gender inequality. This is treated in Chapter 12, where the authors note that much of the literature is concerned with the gender gap in earnings. As they say, this is important, but only part of the story, since there is gender inequality in other forms of income and among those not in paid work, and all these inequalities interact with each other.
See also Chapter 20 where Kanbur discusses globalization and gender inequality. Another important missing topic is that of inequality by race and ethnicity. It is a serious omission that we have not included a chapter on discrimination, although we should note that ethnic cleavages are one of the motivations for the theoretical analysis of polarization in Chapter 5.In introducing considerations such as gender and ethnicity, we are, however, going beyond straight income inequality as pictured in Figure 1. We are abandoning the anonymity that lies behind a Gini coefficient or a top 1% income share. We are asking how unequal income is across various well-identified groups. This is adding a dimension to the inequality concept. Two populations A and B may have the same overall inequality of earnings but the distribution of earnings may be exactly the same for men and women in A, whereas it may be more favorable to men in B. Two countries may have the same share of the top 1%, but in one country they may be all men. World poverty may have fallen, but the number in a particular ethnic group below the poverty line may have risen.
2.2 "Beyond Income" Inequality
Much of the reflection about inequality over the past 15 years or so has been concerned with extending the concept to “beyond income” inequality. As Sen et al. (2010) proposed to incorporate nonmarket dimensions into the measure of social progress, thus going “Beyond GDP,” the point here is also to take nonincome dimensions onboard when measuring inequality.
In addition to the quite remarkable perspective it offers on two centuries of economic thought on income distribution and redistribution, the chapter on the history of economic thought (Chapter 1) reminds us that there may be a historical bias in the way economists see and think about income distribution and inequality. This bias is likely to be as present today as it was in the past. Classical economists focused on functional income distribution among land, labor, and capital because they viewed the society they were living in as made up of classes deriving their income from different factors. This view does not fit well our own world, even though factor rewards and the functional income distribution still features today in macroeconomic distribution theories. Another interesting feature of Chapter 1 is the long-lasting reliance in normative economics on utilitarianism. Itis only relatively recently, i.e., the 1970s, and very much under the influence of Rawls and Sen, which economists have begun to distance themselves from this approach and to consider alternatives.
It is noteworthy that this line of thought developed very much as a major extension of the previous literature on income inequality measurement, a literature that is comparatively young in a historical perspective. Several features of the income inequality measurement “paradigm” as it developed say between 1920 (Pigou, 1920; Dalton, 1920)[3] and the 1980s are worth stressing as it provides a point of reference for modern researchers who seek to extend this paradigm to a higher level of generality in terms of the definition of economic inequality. A first feature is that most properties of inequality indicators, their interpretation in terms of social welfare, and their analogy with risk analysis are now well understood. To be sure, work remains to be done on the income inequality measurement agenda. This volume of the Handbook gives two examples of it: polarization (Chapter 5) and the introduction of statistical methods in the measurement of income inequality (Chapter 8 by Frank Cowell and Emmanuel Flachaire). But considerable progress has been made. A second feature is that this was done rather quickly after the contributions by Kolm (1966, 1971), Atkinson (1970), and Sen (1973). A third feature is that, despite a possible analogy with utilitarianism, the paradigm was explicitly presented as nonutilitarian, even in the generalized sense of a social welfare function, thus breaking with an important and powerful school of economic thought on social issues. Finally, as the paradigm started to develop, its very relevance was questioned. “Equality of what?” asked Sen (1980), suggesting that the income focus was severely restrictive and even questioning the welfare basis for inequality measurement.
Four chapters in this volume of the Handbook deal in different ways with this extension of the income inequality measurement paradigm. The following simple framework is intended to help identify their main contribution, as well as the general issues in moving from income to other, more general, definitions of economic inequality. We first introduce the concept of “functionings,” in the sense of Sen, of individual i, denoted by the vector ai. Functionings include various aspects of life enjoyment: material consumption, health, job market status, housing and environment quality, etc. Among them, let us single out material consumption, as measured by money income, yi, so that ai = (yi,xi) where xi stands for nonmaterial consumption functionings. Let the preferences of individual i among those functionings be described by an ordinal utility ui(yi,xi) function, normalized to unity for some reference bundle a°. Let the “satisfaction” of individual i be an increasing function S[ui(yi,x,), bi] where bi stands for a set of individual characteristics that can influence the satisfaction that individual i derives from (yi,xi). Finally, assume that the economic environment, the technology and social habits are such that the vector of functionings must belong to an individual-specific set Qi defined by yi, xi, and zi, where zi is a vector of attributes of individual i, which may differ from bi. A person may, for example, be able to function at home but not in a formal labor market setting or may come from a social background that broadens her economic opportunities. The set Qi thus describes the set of functionings individual i can reach, given her characteristics. This may include the standard budget constraint as well as the production function that permits the
Introduction: Income Distribution Today xxvii
Introduction: Income Distribution Today
transformation into functionings of the goods and services bought on the market. Let (y*, xi*) be the bundle of functionings preferred by individual i in the set of possibilities, Qi. Of course both y* and x* are individual-specific functions of zi. It is also natural to assume that this preferred vector is also the observed vector of functionings. The corresponding satisfaction of individual i is Vi = S[ui(y*, x*), bi], where the second argument allows for the fact that two individuals may get different levels of satisfaction from the same functioning bundles.
With the aid of this notation, it is then possible to describe the various approaches in the recent literature to extend the measurement of inequality beyond money income and to see their advantages and limitations.4 They are discussed in Chapter 2 by Koen Decancq, Marc Fleurbaey, and Eric Schokkaert on inequality and well-being, Chapter 3 by Rolf Aaberge and Andrea Brandolini on multidimensional inequality, and Chapter 4 by John Roemer and Alain Trannoy on inequality of opportunity.
2.2.1 Defining Inequality on Functionings: Multidimensional Inequality Measurement
Inequality is to be defined on the collection of vectors (y*, x*) in the population. Various approaches can then be used with varying degrees of generality. The most obvious way to proceed is to aggregate the various dimensions into a single scalar and apply standard unidimensional inequality measurement to this scalar. The aggregator function, defined as A(x,y), may be arbitrary, satisfying some basic properties, or it may be related to the framework set out in Section 2.2, in which case it is equivalent to assuming that all individuals have the same preferences, u, and the same characteristics b, so that they have the same satisfaction function, S(u(xi,yi), b), of a functioning bundle (xi,yi). Alternatively, this function of (xi,yi) may be the preferences of the social evaluator. In any case, all individuals are assumed to apply the same trade-offs among the various functionings. Such a normative aggregation approach lies behind several specific multidimensional inequality measures based on some functional form for the aggregator function, as in Maasoumi (1986). The new inequality-extended Human Development Index used in the Development Program of the United Nations (UNDP) (Foster et al., 2005; Alkire and Foster, 2010), or the recent efforts by OECD to measure multidimensional living standards taking account ofinequality, unemployment, and health (OECD, 2014) are examples of this approach. The recent poverty measurement literature based on the counting of deprivations follows the same logic. Deprivations are grouped by functioning, then the number of deprivations and the extent of deprivation in the various functionings are aggregated to
4 It also allows us to distinguish the approach adopted in the inequality measurement literature of defining social welfare in terms of incomes yi from an utilitarian approach where social welfare is defined over 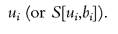
generate an overall poverty indicator for individual i—see Alkire and Foster (2011) and Chapter 3.
Instead of using specific measures and specific aggregator functions, A(x,y) or S(u(x,y),b), it is possible to generalize social welfare dominance analysis in income inequality measurement—the counterpart to Lorenz dominance of income distributions (Kolm, 1977). Following Atkinson and Bourguignon (1982), a partial ordering of distributions of the bundles (y*, x*) in a population may be obtained by considering all the aggregator functions within some class of functions (see, for example, Duclos et al., 2011). As, however, is brought out in Chapter 3 by Aaberge and Brandolini, it is not straightforward to generalize the Pigou-Dalton principle of transfers to the multidimensional case. Moreover, we should not lose sight of the fact that nonmaterial functionings may require different treatment. The choice of aggregator function has to reflect the specific characteristics of, say, health as a variable. For example, health may be measured in ordinal rather than cardinal form, as is discussed by Allison and Foster (2004) and Duclos and Echevin (2011).
2.2.1 Individual Preferences and the Income Equivalent Approach
Interpreted in terms of individual preferences, the preceding approach imposes identical preferences on all individuals. If ordinal preferences are observed, then a particular individual-specific aggregator function can be used which has the dimension of income—see chapter 4 of Fleurbaey and Blanchet (2013). With a reference vector x° of nonincome functionings, the equivalent income corresponding to an observed bundle (yi,xi) is given by the solution yi of the equation: ui(yi, x°) = ui(yi, xi). Such a solution does exist if ui() is reasonably assumed to be continuous and monotonically increasing. The equivalent income is thus a function of the bundle (yi,xi) conditional on x°. It can be handled exactly in the same way as income is dealt with in income inequality measures. Of course, the issue is whether it is possible to estimate individual preferences ui(y,x). In Decancq et al. (2014), this is done using subjective satisfaction data and relating these data to income and observed functionings for individuals with common characteristics in some subset of (bi). Another issue is the choice of the reference nonincome bundle, x°, since inequality measures will be conditional on that bundle—see Chapter 2.
2.2.2 Defining Inequality Using Subjective Satisfaction
Going further along the chain, another approach at measuring inequality is to focus directly on satisfaction levels, Vi = S[ui(y*,x*), bi], as directly observed in satisfaction surveys. This is equivalent to using the individual-specific aggregator function, ui(yi*, xi*), as well as the satisfaction function S(u,bi). Several authors have followed this route, showing for instance that, unlike for observed income, inequality of “happiness” tended to go down over time in most developed countries and, as for income, to be smaller in richer than in poorer countries—see for instance Veenhoven (2005), Stevenson and Wolfers (2008) on the United States, Ovaska and Takashima (2010), Becchetti et al. (2011), and Clark et al. (2012).
Since life satisfaction is generally recorded on an ordinal scale, there are evident problems in converting such measures to a cardinal scale and employing standard inequality indicators. For this reason, an alternative approach based on dominance criteria has been proposed by Dutta and Foster (2013). On the conceptual side, the issue arises as to the interpretation to be given to life satisfaction data. In particular, they may actually reveal the satisfaction of an individual relatively to his or her past experience and future expectations, and also possibly in relation to other individuals. If so they are improper for the measurement of “economic inequality.” In terms of the notation introduced above, it is doubtful whether the individual characteristics bi, which determine how ordinal preferences are cardinalized into satisfaction, should be taken into account in measuring economic inequality. The same bundle of functionings enjoyed by two individuals having the same preferences may yield different levels of satisfaction if one of them has a rather positive and the other a negative attitude toward life in general. A more detailed account of the interpretation to be given to subjective satisfaction data is offered in Chapter 13 by Andrew Clark and Conchita d’Ambrosio.
2.2.3 Inequality of Capabilities
Instead of defining inequality on the observed bundle of functionings (y*, x*), resulting from the choice of individual i in his/her choice set, Qi, one could move upstream and consider the inequality of these choice sets, as in the capability approach. The first step is to identify these sets, as different from the particular point (y*, x*) actually achieved in the set. Presumably, this could be done by considering the set generated by all the functioning bundles observed for persons with the same vector as attributes, z. Assuming that such identification has been made, the second step would consist of defining an inequality measure on these sets rather than scalars, as with income, or vectors as with multidimensional inequality. In practice, the measurement of inequality based on capabilities has been reduced to emphasizing a few components of the vector of individual characteristics, zi, that indirectly define the size of the set Qi. Typically, these are variables like education, health, or the availability of material resources. These three variables are combined linearly at the aggregate national level to define the familiar Human Development Index used by the UNDP to measure the inequality of functionings between any pair of countries. Several attempts have been made to incorporate a larger set of variables at the individual level in specific countries (see, for instance, Anand et al. (2007).
2.2.4 Inequality of Opportunities
Inequality of opportunity is defined as that part of the inequality in optimal functionings, (y*, x*), that is, due to differences in individual characteristics, zi, or possibly in a subset of these variables. Among these characteristics, a distinction is made between variables, on the one hand, that are outside the control of individuals, which are called the “circumstances” faced by the individual, and variables, on the other hand, which may be assumed under his/her control. Then the inequality of opportunity can be measured by the inequality that exists in the (y,x) space across groups of people facing the same circumstances. Those groups are called “types” by Roemer (1998). The simplest measure is obtained by considering the inequality of the mean vector (y, x) among the various types. More elaborate measures would compare the distributions (y,x), rather than means, across types. In Chapter 4, Roemer and Trannoy discuss methods for doing so when focusing on income distribution only. The implementation of this approach requires assumptions to be made about what may be considered as “circumstances” (gender, ethnicity, family background,...) and what may be assumed under the control of an individual (school achievement, for instance). Moreover, there are necessarily unobserved circumstances, so that one can at best measure the income inequality due to observed circumstances. A particular case frequently used is when one considers only one component of zi, like ethnicity. In the space of earnings, the inequality of opportunity then corresponds to the familiar concept of wage discrimination, as is discussed for gender in Chapter 12.
Inequality in terms of opportunity or capability is both defined on an “ex ante basis,” that is among groups of people with some common characteristics, and irrespective of differences in individual achievements in the space of functionings. (In contrast, inequality of outcomes, be they income, earnings, consumption spending or even “satisfaction,” is an ex post inequality concept.) Practically, the main difference between the measurement of the inequality of capability and opportunity is that the former focuses on the inequality in the vectors of attributes, zi, whereas the simplest approach to the latter considers the inequality between mean outcomes (y,x) across various “types” defined by identical “circumstances,” z. A second difference may lie in the individual characteristics selected to differentiate people, determinants of the set of possible functionings on the side of capabilities, and exclusively circumstances outside the control of individuals on the side of opportunity. Recently, there have been a number of attempts at measuring the inequality of opportunity in several countries—for instance, Brunori et al. (2013) have put together estimates obtained for a set of 40 countries using earnings as outcome and family background as circumstances. A related literature, although with more antecedents, is concerned with intergenerational income and more generally social mobility—see Chapter 10. Here too, the issue is to measure the contribution of an observed circumstance, the parents’ social status, the inequality of a particular functioning, and the children’s social status.
Overall, “beyond income” inequality measurement touches upon the very fundamentals of economic inequality and a number of important conceptual advances have been made since the pathbreaking work by Rawls and Sen. Data limitations, the frequent difficulty of translating conceptual parameters into actual figures, and quite often the complexity of the analytical instruments being proposed have limited the empirical applications, but the area is promising for future research. A priority should be the search for simpler ways of making use of the conceptual advances in describing the multiple dimensions of economic inequality without reducing them to a single number.
3.