A.2 Avatamsaka Stochastic Process Under a Given Payoff Matrix
We apply the Polya urn stochastic process to our Avatamsaka game experiment to predict an asymptotic structure of the game. We impose the next assumptions for a while Aruka (2011, Part III).
Assumption 1 There are a finite number of players, who join the game as pairs.
Assumption 2 The ratio of cooperation, or C-ratio for each player, is in proportion to the total possible gains for each player.
As Aoki and Yoshikawa (2006) dealt with a product innovation and a process innovation, they criticized Lucas’s representative method and the idea that players face micro-shocks drawn from the same unchanged probability distribution. In light of their findings, I show the same argument in the Avatamsaka game with different payoffs. In this setting, innovations occurring in urns may be regarded as increases in the number of cooperators in urns whose payoffs are different. Moving on from a classical Polya urn process with a given payoff matrix (Aruka 2011, Part III), we then need the following formulae:
Ewens sampling formula (Ewens 1972) A K-dimensional Polya urn process with multiple payoff matrices and new agents allowed to arrive.
Self-averaging Eventually, however, players’ behavior can be independent of others’.
Pitman’s sampling formula Two-parameter Poisson-Dirichlet distribution. Non-self-averaging The invariance of the random partition vectors under the properties of exchangeability and size-biased permutation does not hold.
According to Aoki and Yoshikawa (2007, p. 6), the economic meaning of nonself-averaging is important because such models are sample-dependent, and some degree of impreciseness or dispersion remains about the time trajectories even when the number of economic agents reaches infinity. This implies that focus on the mean path behavior of macroeconomic variables is not justified, which, in turn, means that sophisticated optimization exercises that provide us with information on means have little value.
We call an urn state self-averaging if the number of balls in each urn could eventually be convergent.Definition A.1. Non-self-averaging means that a size-dependent (i.e., extensive in physics) random variable X of the model has a coefficient of variation that does not converge to zero as the model size tends to infinity. The coefficient of variation of an extensive random variable, defined by
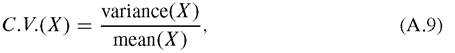
is normally expected to converge to zero as model size (e.g., the number of economic agents) tends to infinity. In this case, the model is said to be self-averaging.
A.2.1 Avatamsaka Stochastic Process Under Various Payoff Matrices
Next we introduce various payoff matrices into our Avatamsaka process. Let various types of different sized payoff matrices be 1, ∙ ∙ ∙, K. We then have similar gainratios of players with different payoff types for each number of agent with gain i. Every player who encounters an opponent must draw lots from any lottery urn. A couple of players can draw a lot arbitrarily, and then return them to the urn. It then holds that the greater spillover does not change Avatamsaka characteristics. However, different spillovers may change the players’ inclinations and reactions as shown in Fig. A.3. It is noted that we can get a PD game by extending the PR line to the north-east.
Suppose there are a number of different urns with various different payoff matrices, each of which has its own spillover size. A different spillover in our Avatamsaka game may change the inclinations of the players, but these inclinations are not necessarily symmetrical. An urn with a greater spillover might sometimes be more attractive for a highly cooperative player, because the players could earn greater gains in size. A less cooperative player might prefer to enter an urn with
Fig. A.3 Spillovers in Avatamsaka payoff matrix. See Aruka and Akiyama (2009, Fig.
9)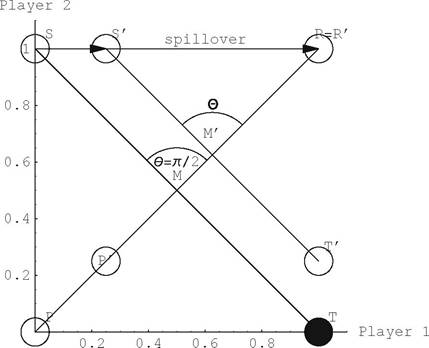
a smaller spillover in a much higher level of cooperation, but he can change his mind and defect. Players may therefore have various plans. Any player depends on the state in which he remains or enters, while an urn, i.e., a payoff matrix, occurs stochastically.
By the time the i -th cooperation occurs, the total of Kn payoff urns are formed in the whole game space, where the i -th payoff urn has experienced cooperation for i = 1,2, ■■■, Kn. If we replace “innovations” with “increases in cooperation”, then by definition the following equality holds:
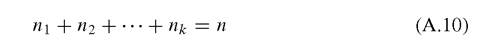
when Kn = k. If the n-th cooperation creates a new payoff matrix (urn), then nk = 1, and
So there are a finite number of urns into which various types of payoff matrices are embedded for 1,2, ∙ ∙ ∙, Kn.
In this new environment, we can have n inventions to increase cooperation. In other words, the amount of cooperation xi in urn i may grow, because of stochastic multiple inventions occurring within it.
Assumption 3 (Aruka and Akiyama 2009, p. 157; Aruka 2011, p. 257) Cooperation accelerates cooperation, i.e., the greater the cooperation, the larger the total gain in the urn will be.
Because of an Avatamsaka property, we can also impose another assumption.
Assumption 4 (Aruka and Akiyama 2009, p. 157; Aruka 2011, p. 257) A player can compare situations between the urns by normalizing his own gain.
Under the new assumptions, we can prove the non-self-averaging property in our Avatamsaka game as

Here β = log(y) > 0. It turns out that Xn depends on how cooperation occurs. Finally, according to Aoki and Yoshikawa (2007), the next proposition also follows:
Proposition A.1. In the two-parameter Poisson-Dirichlet model, the aggregate cooperation behavior Xn is non-self-averaging.