C An Inference Engine
Science is concerned with causes, not correlations, and yet our data are mainly about correlations among variables. Judea Pearl is a mathematical statistician and A. M. Turing Award Winner10 who finds this situation manifestly unsatisfactory.
He wants to deal directly with causes and causal inferences, so he invented a theory of causation, the Structural Causal Model (I'll call it a “causal model”), a calculus for expressing causal relationships and methods for solving problems involving causal relationships.11 What is a causal relationship? If two variables, say children’s ages and their heights, are correlated, it just means that they change together. Their relationship is symmetrical, and it doesn’t matter how you plot them on a graph, with age on the x-axis and height on the y-axis or vice versa.A causal relationship is not symmetrical, if A causes B, then it is not true that B causes A. If being young causes males to engage in risky behavior, you show this by plotting age on the x-axis and risky behavior on the y-axis. You can’t flip the axes because it is not the case that engaging in risky behavior makes you young (although you wouldn’t know that from observing certain older males).
The causal model incorporates features of Bayesian networks, Bayesian inference, and more. Pearl wants to program “brainless” robots to behave as if they understood causality and act appropriately. As it stands, robots and computers in general do not take hints, infer unstated assumptions, or know “what you mean.” How many times have you been frustrated to get no hits in an online search until you realized that one tiny spelling error was to blame—what you meant was so obvious! How could the stupid computer not have known? Enabling machines to operate as though they could think causally would be a giant step toward harnessing the power of Big Data.
What we need is an approach that is not based on black-or-white Boolean rules, but on Bayesian probabilistic rules (see Chapter 6) that can be updated with experience and that respond with shades of gray. Pearl’s solution is to create systems of equations, called Bayesian networks, of conditional expressions for variables—both observed and “latent”—that interact. This approach expresses relationships quantitatively and relates them to diagrams—directed acyclic graphs (directed graphs)—that illustrate possible causal paths from one state to another. These paths are meant to be actual, asymmetrical, causal relationships, where A causes B, not just that A and B are correlated.
A basic example of a problem that Pearl solves with a Bayesian network is this: you know that the grass will be wet if it either rains or the sprinkler system goes on. You also know that, if it rains, the sprinkler system most likely won't be turned on, though it might (i.e., there is a one-way causal interaction between rain and the sprinkler system, but it isn't perfect). There are prior probabilities that rain, sprinkler operation, or both will take place. This is a conditional probability: the chance that one event (rain) happened given that another happened (sprinkler on). Both rain and sprinkler can cause wet grass so, if the grass is wet, you can assume that the probability is 1.0 that one or both events occurred. Each state of the world is represented by a node in the graph (Figure 15.112), and each arrow shows a causal relationship. Suppose you want to determine the chance that the grass is wet because it rained. The legend to Figure 15.1 sketches out how you would get to the answer from the conditional probability distributions. Now imagine that you want to understand an event and have a dozen, or hundreds,
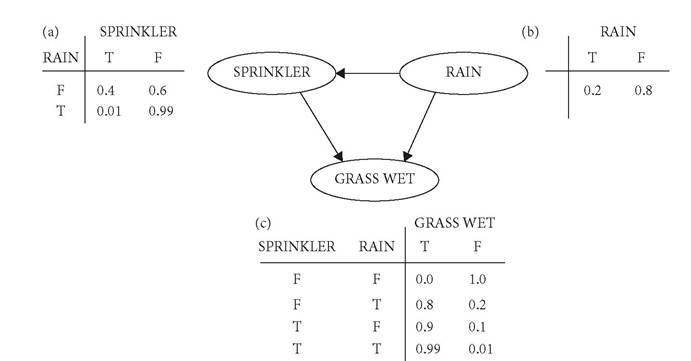
Figure 15.1 A basic Bayesian network illustrating how causal interactions among conditions influence outcomes.
The tables show the conditional probabilities of the events: “T” means it happens, “F” means it doesn't. Table A says that the probability that if it rains (Rain = T) the chance that the sprinkler is on (Sprinkler = T) is 0.01. Table B says that the chance that it will rain is 0.2. Table C says that if the sprinkler doesn't go on (Sprinkler = F) and it doesn't rain (Rain = F), the grass won't get wet (Grass Wet = F). With these tables you can calculate the probability that the grass will be wet if it rains (sprinkler on or off) and the probability that the grass will be wet given any condition (sprinkler, rain, both). Dividing the probability of “wet given rain” by the probability of “wet in any condition,” (i.e., the probability of “wet given rain” plus the probability of “wet given no rain”) your answer to the question, “If the grass is wet, what is the probability that it rained?” is approximately 0.36.of causal variables that interact, like the rain and the sprinkler did. Even with a directed graph, the true causal relationships won't be intuitively obvious, whereas solving the system of equations outlined by the graph will give you a group of probable causes for you to evaluate.
The causal model does more than set up networks of conventional Bayesian equations: it describes a new mathematical framework, a do calculus for stating and solving counterfactual equations (we encountered counterfactuals in Chapter 11.A.2.c). You'd use counterfactual reasoning in trying to infer “what would happen if” you do some manipulation. The problem is that you can't express “what if” statements in ordinary computer notation, yet that's what you need to make “stupid computers” understand what you mean. The do calculus lets you put such sophisticated intellectual concepts into computer-friendly syntax. For instance, the concept “what if” implies a joint probability distribution that tells you the likelihood that Y event will happen given that a treatment value X occurs.
As far as the computer is concerned, this is an asymmetrical, causal relationship because the value of Y does not affect the value of X.What's more, with Pearl's methods, you can go beyond observable variables to investigate hidden, latent variables that you can't measure directly. Say you wondered about switching Snowball's dog food to a cheaper brand than the expensive one he snaps up so readily. You reckon that if Snowball is hungry enough, he'll eat anything, so food deprivation alone, the need to replace the calories he uses up, would make him eat. On the other hand, you recall your grandmother saying “hunger makes the best sauce,” thus, in Snowball's case, if his food tastes better he'll eat more of it. But does the more expensive food really taste better to him? Your grandmother's principle suggests the hypothesis that both his state of food deprivation—how long its been since he last ate and how many calories he's burned since then—and the tastiness of the food interact to determine how much he eats. Your model of his eating behavior would include a causal relationship between food deprivation and the latent variable “tastiness”; if he's hungry even bland food will taste better. Constructing a causal model makes it easier to see links between variables that might be crucial for explaining the phenomena that interest you.
The main point for us is that a causal model is upstream of scientific hypothesis formation and can provide clues about hypotheses to test. The hypothesis about Snowball's eating predicts, for example, that he'll eat more cheap food if he's hungry than what he'd need to make up for the calories he's burned. The model highlights the relationships among the variables, which leads to testable hypotheses. Testing the predictions can falsify the hypothesis, although, as usual, if the causal model fails then you won't know which of its assumptions were wrong—maybe you didn't assess Snowball's taste variable appropriately or maybe other factors also influence his eating.
Pearl's approach is a probability-testing procedure that depends heavily on subjective prior probabilities, so it is open to the criticisms of Bayesian approaches that we discussed in Chapter 6. Nevertheless, the causal model is a rational approach to problem-solving with Big Data that is far removed from the correlation-only methods of the Big Data Mindset. Pearl's ideas have contributed to the development of AI, which is devoted to using computers to mimic human reasoning ability. This is the second way in which Big Data will profoundly affect scientific thinking and the hypothesis.
15.