D Artificial Intelligence and the Hypothesis
In the beginning, computers were just machines; nobody wondered if they could think. A computer crunching gigantic masses of data and plotting the results is no more than a useful tool.
When the IBM computer “Deep Blue” beat the reigning world chess champion, Gary Kasparov, in May 1997,13 it could be shrugged off because chess is a well-defined, rule-based game, albeit with an enormous number of possible moves and positions. The computer program used brute force augmented by programming heuristics to evaluate 200 million positions per second. Definitely impressive, though since machine performance often exceeds human performance in other ways, the defeat was not especially threatening to the human ego.When the IBM computer “Watson” beat the champion of the TV game show Jeopardy, Ken Jennings, in February 2011,14 in a test of ability to answer factual questions posed in natural language terms, computer encroachment on human turf became a little more ominous. Although it, too, was relatively structured, the Jeopardy competition was markedly less rigid than a chess game and, except for a few notable gaffes, Watson won going away.
And computers are demonstrating humanoid capabilities in far less structured environments. Recently, an IBM computer, Project Debater, did well against the 2016 Israeli national debate champion, Noa Ovadia,15 in a match where neither party knew the topic in advance. Both had to marshal evidence from their background knowledge—no internet hook-ups—and frame their arguments in logically compelling ways while anticipating and counteracting the opponent's arguments. Project Debater didn't win but firmly held its own, as Watson, and many humans, never could have. Oddly, perhaps, success in debate doesn't automatically translate into earning power; IBM is still trying to find a business application for Project Debator that will make money for the company.
In any event, the machines are obviously succeeding in handling the demands of increasingly abstract environments.In some ways, scientific thinking occupies a mid-point between structured and unstructured activity. It has rules and objectives, and it draws on relatively well-defined background information; it also depends on an ability to go beyond the information given and discover new knowledge. Scientific thinking is potentially very fertile ground for the combination of Big Data and AI.
15.D.1 Machine Learning and Neural Networks
“Machine learning” (aka AI) is shorthand for a collection of programming strategies that allow computers to improve their performance in solving problems by trying a solution, comparing that solution with a standard, getting feedback on how they did, and then automatically modifying their programs, trying again, etc. One scheme is a neural network16 that simulates a network of brain neurons. Each conceptual neuron receives and processes incoming bits of information in the form of either plus or minus values, analogous to neuronal excitatory and inhibitory signals. After summing the information each neuron sends its result to other neurons that process the information that they receive and pass it along until the network calculates a final output.
A simple network might have one set, one layer, of interconnected neurons. Complicated networks, deep neural network (henceforth, I'll use “neural networks” or “networks”), have many layers. The neurons in each layer process a certain kind of information, and the layers communicate, forward and backward, until ultimately their summed activity generates the output of the network. The program compares its output with the concept the neural network is trying to “learn.” The difference between the actual and criterion output constitutes a feedback signal that is routed back to the individual neurons and alters both the way they will process new information and the strengths of their interconnections.
This is machine learning.Let's say you want to teach your neural network to recognize a picture of a cat. You feed in many, many pictures of different cats doing all of the adorable things that cats do. This is your training set and the bigger, the better. You label each picture as “cat” or “not a cat” and have an algorithm process the data. A neuron in the network gets information from a particular pixel in every picture for all of the pictures in the training set. Every now and then you feed in a new picture that the network has never seen and ask it, “Is this a cat?” The networks output says “yes” or “no” and, depending on whether it was right or wrong, modifies the strengths of its own internal neuronal connections. You keep going like this until you're satisfied that your network can reliably identify a cat. Neural networks can become quite good at pattern recognition, speech perception, etc., and they have been used to guide selfdriving cars or write credible newspaper articles.17 This is all harmless and nonthreatening (unless, maybe, you drive vehicles or write about sports for a living).
“Deep learning” is a merger of deep neural networks and Big Data, and it is ordinary machine learning on steroids.18 Deep learning is “unsupervised,” meaning that if you want your neural network to learn “cat,” you don't label the pictures that you use to train it on. Instead, you feed in say, 10 million pictures with a cat in them and instruct the algorithm to find out what's common about them. Eventually it comes up with “catness” all by itself. Unsupervised machine learning like this takes place in a way that, almost by definition, even its human programmers don't understand. Still, it's about cats and we know what cats are. Things grow increasingly problematic as we move to the next level.
15.D.1.a What Deep Learning Can Learn About People that People Don't Know About
Deep learning networks can learn things that people don't know about, according to Stanford social psychology researchers Yilun Wang and Michael Kosinski, who wondered what our faces really say about us19 and turned to Big Data and a deep learning network to find out.
First, they loaded it up with data on 35,326 American men and women—50% heterosexual and 50% gay— collected from online dating sites, complete with pictures and other information including self-identified sexual orientation, dating aspirations, etc. Then they asked their network if there were any correlations between faces and sexual preferences as defined by the online data; the objective was to see if the computer could learn to determine someone's sexual preference by just looking at his or her face. Now, if you ask average people, gay or straight, to guess whether they are looking at a picture of a gay or straight person, they are correct a little more than half of the time, usually from 55% to 61%. After seeing just one photo of a person, the computer program utilizing a deep learning network was right 81% of the time for men and 71% of the time for women. If the program was shown five photos of each person, its success rates went to 91% and 83% for men and women, respectively.This astonishing result shows that machines can greatly outperform people on a task that, you would have thought, demanded the special perception that only a sensitive, experienced human could have. This feat, while amazing, is not the creepiest part. What is far more unsettling is that the researchers themselves had no idea what specific information their network was picking up in people's faces—obviously there is something in faces that people themselves are oblivious to.
15.D.1.b What, If Anything, Can We Do? The European Union Takes a Step Wang and Kosinski's study stirred up a lot of anxiety among groups concerned with personal privacy; nevertheless, the profiles that were analyzed had been made public by their owners. The message, you might at first assume, is be vigilant and cautious when you make your personal data public. But is this even possible anymore? Big Data are being scooped up from every nook and cranny of our lives, and cameras are found in more and more places in our society.
Computer programs like Wang and Kosinskis would work on millions of faces whose owners have never intentionally advertised themselves publicly. The fact that nobody could say how the program works only made it seem more like a tool of Big Brother.Privacy concerns, as well as the general question of what the machines are up to, moved the European Union (EU) to enact a law,20 effective May 2018, that the public has a right to an “explanation” about how a machine makes a decision that affects people. While it may seem straightforward, if you think about the complexity of deep learning networks, the massiveness of Big Data, and the ability of computers to find correlations that the human mind may not be able to grasp, you can see that the requirement for explanations may be a tall order. So tall, in fact, that it has inspired the creation of a new branch of AI, one specifically designed to investigate and let the public know what the original networks are doing.21 Called “explainable AI” or XAI, the strategy is to put a new algorithm, let's call it xDLN, inside the same computer that is trying to learn, for example, “cat” via the concept-acquiring network, “cDLN.” The xDLN will watch the cDLN to see what feature of each image makes each neuron light up as the cDLN gradually develops its concept of catness. By training the xDLN to recognize and label the cDLN's operations, the hope is that the xDLN will be able to tell us what the cDLN is doing so we can understand and explain it. (If you fear that we might need a “yDLN” to understand “why” the xDLN is doing what it's doing, and so on and on, you're not alone.)
Even if XAI functions in the way that it's supposed to, we still won't know whether it can give us an “explanation.” In fact, whatever an “explanation” is in this context, it seems be a long way from the naive notion of “explanation” that we've assumed up to now. If an only dozen experts and a hyper-advanced computer program “get it,” has it been adequately explained to the public? The EU law doesn't say, evidently preferring to let the legal system sort things out.
Skeptics think the very principle of explanation must be carefully refined.22 They distinguish between “subject-centered explanations” that focus on telling us, the technically illiterate masses, approximately what the computers are doing in language we can understand and “machine-centered explanations” that (may) tell the experts in excruciating detail what is happening. Subject- centering sounds palatable, though perhaps broad and fairly superficial, and it will leave the experts in charge. The skeptics doubt that having a “right” to an explanation is the best solution to the looming threats potentially posed by the machines' growing level of influence over our lives. Rather, they say, we'll be better off if we insist on establishing and enforcing workable, but iron-clad privacy rules that set limits on what the machines can know about us. Instead of seeking an explanation of how computers infer people's sexual orientation, people should be enacting laws that will prevent computers from gathering the relevant information in the first place.
The decisions that society will have to make in response to the rise of Big Data and AI mirror the decisions that science itself will have to make. How much do we trust AI? How much autonomy do we turn over to it? What roles will humans have when we can no longer comprehend AI's information processing capabilities or it outputs? An alternative for science lets us put off the thorniest of these issues at least for the time being. This is the way of the Robot Scientist, where technology extends the capacity of humans to do their jobs without completely overturning the current order.
15.D.2 The Robot Scientist
The Big Data and AI revolutions are surely coming to biosciences, cognitive sciences, and more and will change everything when they do. Indeed, the day of the “Robot Scientist” in biology has arrived.23,24 Guided by AI techniques, Robot Scientist “Adam” has successfully carried out genetic experiments on yeast cells. Not impressed? Consider this: Adam can come up with hypotheses to explain observations, devise experiments to test these hypotheses, physically run the experiments, collect and interpret the data, and then repeat the cycle. And Adam does his work “on time and under budget,” meaning he also calculates and conducts the most cost-effective ways of testing his hypotheses. Essentially, after hitting “Enter,” humans have no role in Adam's investigations apart from supplying him with raw materials and clearing away experimental waste every five days.
15.D.2.a The Robot Scientist and What He Does
Despite being called a “robot,” Adam is a fully equipped mini-lab rather than a humanoid machine; he controls a suite of laboratory instruments and devices, including a -20oC freezer, three cell incubators, two plate readers, three liquid handlers, three robotic arms, two robot tracks, a centrifuge, a washer, an environmental control system, cameras, computers, and more. He can design and carry out approximately 1,000 experiments and make more than 200,000 observations per day. Continuously.
In his basic protocol, Adam selects specified yeast strains from the thousands of mutant strains in his freezer and puts them in tiny plastic wells on plates. The wells contain “rich” (having all necessary nutrients) growth medium. He measures the cells' growth optically, first on rich medium, then takes a defined quantity of the cells, transfers them to wells lacking a particular nutrient, and measures their growth again.
As an example, Adam's was given the task of identifying the yeast genes that encode several “orphan” enzymes (i.e., nobody knew which genes were necessary to make or “encode” them). The general plan of his experiments was conventional, though a bit technical.25 We don't need all the details to get a sense of how he works, so here's a sketch: Adam's developers knew of an enzyme that makes the amino acid lysine, but didn't know which gene encoded for that enzyme and they set Adam the task of finding it. Adam started by choosing a mutant strain of yeast that can't make lysine and can't grow without it. He consulted his database to look for biochemical reaction pathways that might lead to the synthesis of lysine and systematically supplied the cells with the ingredients that each pathway required, one ingredient per well of mutant cells. If the cells lacked a particular ingredient to produce lysine, they grew more rapidly when Adam gave it to them, and he detected their increased growth rate. From knowing which reactions require that ingredient, Adam found out which enzymes carried out those reactions. By proceeding in a step-by-step way and by doing many, many experiments, Adam identified all of the enzymes in each biochemical pathway. Then, since one particular gene codes for each enzyme, he deduced which gene or genes had been necessary for each pathway.
Adam then “hypothesized” that each gene he had deduced was responsible for lysine production, and he tested each hypothesis. In the end, he generated and tested 20 hypotheses and ended up concluding that lysine was produced by the activity of three genes that nobody had known were required for lysine production. Human scientists subsequently confirmed Adam's conclusions experimentally.
Adam had copious background information, a logical model of yeast metabolism, a bioinformatics database, and programming software so he could carry out “abductive” (see later discussion) and deductive reasoning and design experiments. He could also record, store, and analyze his results; perform statistical tests; and relate the results to his hypotheses. Rejecting (i.e., falsifying) hypotheses was a crucial step in the process. There was even a dedicated program to translate Adam's computer-coded ideas—he is a robot!—back into natural language to provide a “human-friendly summary of the formalization” of what he did.
15.D.2.b The Robot Scientist and the Hypothesis
The computer programming that guides Adam demands translation of abstract concepts, such as “cause,” which I mentioned in the last section, from natural language (“text”) into equations that robots can interpret. Research hypotheses must be “represented”26 in robot-friendly ways. The natural language textual definition of hypothesis that Adam works with is more expansive than ours and includes multiple layers of “granularity” that range from informational statements about what is to be tested” to what we've been calling “predictions” (e.g., statements about yeast growth rates).
But what, for Adam, constitutes a hypothesis, and how does he reason? The reality is that Adam selects hypotheses as much as he originates them. “An annotated genome is essentially a large set of hypotheses,” according to two of his developers.27 Adam needs to have an exhaustive set of potential hypotheses to start with. This does not mean that each hypotheses must be fully formed, but it does require that all of the components that would make up hypotheses that he can use be available for him to manipulate. While this may seem opaque, his general process is fairly straightforward. Let's go over an example.
If Adams knows about metabolites A, B, and C and enzymes D, E, and F, he can work out all possible paths from any enzyme to any metabolite, even paths that have never been proposed before. Once he has a plausible set of metabolites and enzymes, he can deduce the gene(s) responsible by going through the steps outlined in the previous section. He cannot imagine the existence of an unknown metabolite with novel properties outside of his knowledge base, meaning that he could not have been the first to discover, for example adenosine triphosphate (ATP), the energy source that many of his enzymatic reactions depend on. In fact, a major impetus for developing Adam in the first place was that he could execute the huge numbers of mind-numbing logical operations involved in inferring interactions among biochemical pathways, thus freeing up human minds for the truly creative work.
15.D.2.C How Does Adam “Think?”
Fundamentally, Adam uses “abduction,” a category of logic invented by the philosopher Charles Peirce that is meant to encompass thinking that is neither inductive nor deductive; basically, Peirce wanted a name for whatever it is that happens when we have a new idea. The philosophical status of abduction “is not settled.”28 As I suggested in Chapter 1, cognitive concepts like abduction generally refer to the external circumstances, the behavioral situation, in which you'd tend to use the term and not to as yet unknown mental operations.
Adam's logic works like this: think of his database of yeast metabolism as a directed graph, like the one in Figure 15.2. It has circles for metabolites A, B, and C, and lines for enzymes D, E, and F that convert one metabolite into another. Let's assume that he wants to discover how C is produced in the cell, meaning he needs to find a path through the graph that goes from metabolites and enzymes to C. From his experiments he has deduced that (1) enzyme D produces A, but
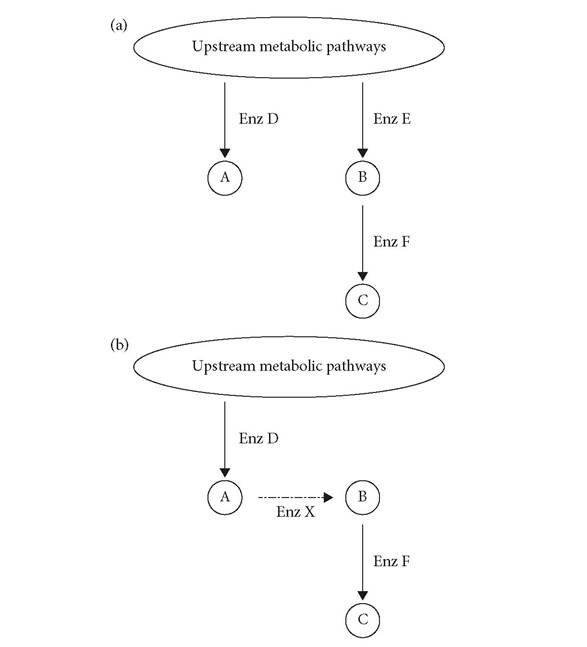
Figure 15.2 Diagram illustrating how Adam, the Robot Scientists, solves problems in yeast genetics.
(a) A tiny part of the graph of all metabolic paths in a cell showing the production of three metabolites A, B, and C (small molecule required for growth) and three enzymes, D, E, and F. Enzymes D and E produce A and B (only) by acting on unknown upstream metabolites. Enzyme F catalyzes the conversion of B into C.
(b) Enzyme E was deleted from this cell, but stimulation of A can produce C indirectly Adam could conclude that a previously unknown enzyme, Enzyme X, converts A into B when Enzyme E is inactive.
not C; (2) enzyme E produces B, and (3) enzyme F converts B, but not A, into C. However, he also finds that, if enzyme E is eliminated, stimulating enzyme D leads to the production of C, which poses a potential problem because there is no known path from enzyme D to C. Adam might hypothesize that a “missing enzyme,” enzyme X, converted A to B (and then enzyme F converted B to C, as usual). If his database includes information on genes from any organisms that encode for an enzyme that converts A to B, he looks for a yeast homolog of that gene; the yeast homolog gene is the basis of a hypothesis.
Of the many hypotheses that Adam generates to explain how C could be produced, he selects ones to test according to how consistent they are with the data he has, their prior probabilities (the Bayesian parameter again) of being correct, and how much they cost to do (he goes for the least expensive). Adam then tests and rejects hypotheses using rigorous, though conventional, statistical standards. His scientific procedure seems impeccable, and it enables Adam to discover new facts (e.g., a “novel” gene coding for enzyme X in yeast metabolism—not really a new gene, but an old one in an unsuspected role).
Of course, Adam has his limitations. First, his database must have all of the background information he’ll need. If he hadn't found existing evidence for enzyme X, he’d have been stuck; he can manipulate established material, even in novel ways, but he can’t originate truly unprecedented concepts. Second, Adam’s conclusions are susceptible to the drawbacks that statistical testing as a whole suffers from (Chapters 5 and 7; e.g., errors because of noise). Worse, however, is that once Adam has tested and falsified a hypothesis, he deletes it from his universe of possibilities, whereas a human scientist, knowing that falsification is never final, would keep it in the back of her mind because fresh data might suggest that it is right after all. Third, if none of Adam’s hypotheses pans out, he concludes there must be an error somewhere and starts “backtracking,” going over what he’s already done, because his a priori assumption that he has a complete set of all relevant hypotheses leaves him no alternative. A human scientist might go looking in an entirely different direction to find clues about how to proceed. Fourth, Adam is specifically designed to do studies on yeast, and most of biology works with tremendously more complicated organisms, hypothetical explanations, and experimental techniques, and it is far from certain how rapidly other disciplines will be able to adopt Robot Science methods.
Nevertheless, Adam is an impressive achievement and, despite his relatively limited range of present applications, the Robot Scientist project does offer useful lessons for science in general.29 Science can benefit by more uniform methods of recording and storing data, the kinds of things that Adam does automatically. The project underscores the importance of the hypothesis by showing that science can progress rapidly when scientists express their hypotheses “explicitly, unambiguously, and completely” and that “the hypotheses that have been rejected contain information about the domain of study.” The project also emphasizes the importance of “negative data” and the reasoning that leads to it, as these facilitate future work. By taking over the rote aspects of scientific thinking, Robot Science will encourage more humans to think outside the box.
15.
More on the topic D Artificial Intelligence and the Hypothesis:
- Alger Bradley E.. Defense of the Scientific Hypothesis: From Reproducibility Crisis to Big Data. Oxford University Press,2020. — 449 p., 2020
- Index
- Notes
- Epilogue
- References
- References
- Anthropomorphic Bias
- Bibliography
- Index