D Kinds of Science: Hypothesis-Based Versus Non-Hypothesis-Based
A critical dividing line between kinds of science is between hypothesis-based and non-hypothesis-based science. Non-hypothesis-based sciences include Discovery Science, which is undertaken when there are too few data for focused hypothesis testing, as well as some of the approaches classified as Big Data that, ultimately, dispense with hypotheses, in part because there are too many data and they are too complex.
However, Big Data is also used in conventional tests of hypotheses, which I'll discuss in this chapter, and I'll postpone consideration of the “Big Data Mindset” until Chapter 15.Whereas Discovery Science and hypothesis-based science are mutually exclusive, they both may be associated with Big and Small Science and with Big and Little Data. The tree diagram in Figure 4.2 is one way of seeing their relationships.
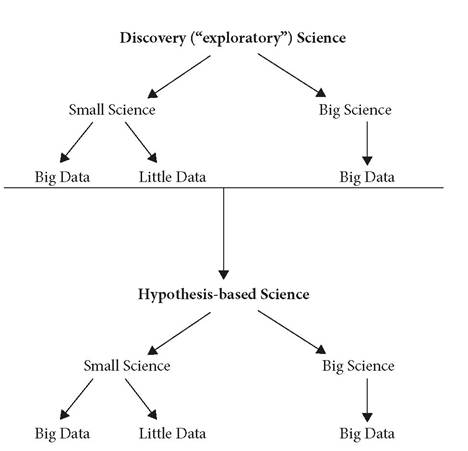
Figure 4.2 Diagram of the relationships among Discovery Science, Hypothesisbased science, Big and Small Science, and Big and Little Data.
4. D.1 Discovery Science
Discovery Science opens up new areas of inquiry; it identifies and catalogs the core elements of an area of research and characterizes their interactions. In principle, Discovery Science ranges in scale from small exploratory studies to gigantic Big Science projects: it seeks to classify and catalog, not to explain. You need to have some discovery before you can do hypothesis testing. I capitalize Discovery Science merely to set it apart; I don't know any self-identified “Discovery Scientists” and, on the contrary, believe that most scientists shift fluidly back and forth between Discovery and hypothesis-testing modes. Examples will follow.
4. D.1.a Discovery Science Versus Hypothesis-Based Science
Almost no one today seriously suggests that hypothesis-based science does not need basic information to work on (see Chapter 10.B for a counterexample).
Even the classical Greek philosophers who wanted to understand planetary motion did not merely sit and contemplate. Their Discovery Science inquiries consisted of looking up at the night sky and keeping records.While a purist might insist that Discovery Science and hypothesis-based science do not overlap, these dissimilar modes of conducting science are related in two ways. First is the one we've been talking about. Discovery Science is the feeder mechanism: it provides the data that hypotheses are designed to explain. Second, Discovery Science necessarily assumes the truth of certain (deep implicit) hypotheses before it can discover anything.
In biology, you can often identify formal Discovery Science projects by the “ome” or “omics” in their names34 (e.g., “genomics,” “proteomics,” “metabol- omics,” and “connectomics”). Discovery scientists typically start by inventorying the constituent elements of a system, identifying, and organizing them. Like European explorers in Western history during the Age of Discovery who set sail with only the vaguest notions of what was before them, Discovery scientists cannot be confident about what they might find. No explicit hypotheses are necessary or even possible at this stage.
4. D.1.b Discovery Science/Big Science
The archetype of a Discovery Science project on the Big Science scale was the Human Genome Project,35 a multibillion dollar, multinational, multiyear collaboration among thousands of scientists. The human genome consists of about 3 billion molecules called base pairs that encode the genes and bits of DNA that regulate the genes. Strings of genes make up chromosomes, and scientists originally used biochemical methods to investigate how they go together in sequence on the chromosomes, one molecule at a time. The Human Genome Project adopted the then-new tactic of breaking down (“shot-gunning”) the long genomic DNA strings into small pieces, deducing the gene sequences of the pieces, and conceptually reassembling them into the original strings.
The Human Genome Project procedure was like manufacturing a machine by assembling small parts into modules and putting the modules together to make the final product, whereas previous methods resembled traditional manufacturing methods of building the machine from scratch, one bolt at a time. The Project required enormous effort and quantities of computing power. It combined DNA samples from multiple individuals because its goal was to determine the sequence of an average human genome, not that of any particular person.4. D.1.C Discovery Science/Small Science
Small Science also engages in Discovery Science, as the example of an investigation of RNA viruses inhabiting spiders found in western Washington state36 showed. The investigators in a small lab were motivated by a general concern with the spread of viral disease, which can infect vertebrates, including humans, as well as spiders. Spiders in general are “undersequenced,” and nobody knew much about the viruses that the target spiders harbored, except that their genomes were made of single strands of RNA, not double strands of DNA, and had about 10,000 bases instead of the 3 billion base-pairs in humans. The investigators obtained rough viral genome sequences, which enabled them to identify six new species of Picornavirus constituting a putative new virus clade; apart from providing a window into “the greater invertebrate virosphere,” the work had no immediate application.
Like the Human Genome Project, the spider virus project investigated a scientifically significant problem and obtained information that could later lead to hypotheses for testing, though, at this stage, nothing was tested and there was nothing to falsify. The final important point here is that although Discovery Science projects are, strictly speaking, not within the scope of the methodological unity described by Popper, they are clearly integral components of science. They complement rather than supplant his vision.
And yet the data provided by Discovery Science do more than provide the foundation for the hypothesis; they constitute a virtual provocation to form hypotheses, as the next section shows.
4. D.2 From Discovery Science to Hypothesis
We cannot resist generating hypotheses once we have some data; it is an innate urge that is part of our built-in survival skill set (Chapter 12). We continually try to understand the world around us. Once scientists have discovered a new phenomenon, they immediately get to work trying to explain it. Discovery Science motivates the formation of hypotheses. A perfect example is the study of the human gut microbiome, which began with a general survey and classification of the varieties of bacteria inhabiting our intestines.
4. D.2.a The Human Microbiome from Discovery to Hypothesis
To understand the mammalian gut biome, investigators are sequencing the genomes of thousands of species of microbes.37 Initially, the microbiome project was pure Discovery Science. Scientists in the Human Microbiome Project isolated microbes, sequenced their DNA, deduced and identified their genes; in all, there were more than 10,000 species, and particular kinds were associated with particular physiological functions. For instance, bacteria can digest a polysaccharide, a kind of starch-like carbohydrate molecule found in plants that we humans can't digest by ourselves. We need bacterial help to be able to use the starch for food.
Importantly, the Human Microbiome investigators found that some bacteria were more effective than others at various tasks. Although Discovery had been their initial motivation, the investigators immediately guessed that variation in the number or types of bacteria could affect human health. One specific hypothesis was that obesity could be caused by the gut microbiome, and it predicted that the microbiomes of obese and lean people would differ systematically. This prediction was soon confirmed. But the hypothesis also predicted that the microbial differences were causal, not merely correlational; it wasn't just that specific populations of bacteria go along with obesity or leanness but that the bacteria help cause these body types.
To test this prediction, the investigators turned to animal models because they could manipulate the animals' microbiomes and they couldn't do that with people. There are three strains of genetically programmed mice that were useful: one was obese, one was lean, and one had no gut bacteria at all.First, the hypothesis predicted that mice that completely lacked bacteria would be at a severe metabolic deficit because they couldn't efficiently extract energy from food, and indeed, these mice were thin and frail. Second, the hypothesis predicted that obese and lean microbiomes would differ, and that was also true. Third, to test the prediction that the gut microbiomes determined the body types, the investigators transferred microbes from obese or lean mice into the mice with no gut bacteria. The results again were consistent with the causal hypothesis: the mice that received bacteria from obese mice gained weight, but if they received bacteria from lean mice, they didn't.38
Finally, to test the prediction that the microbiome influenced human obesity, investigators turned to patients who were suffering from an infection of Clostridium difficile (C. diff.). The gut microbiomes of these patients are seriously disrupted but can be successfully treated with a technique—fecal microbiota transplant39—that transfers intestinal microbiota from healthy individuals to patients. Amazingly, as in the mice, obese transplant donors pass on a tendency to obesity to human recipients.40
The story of the human gut microbiome research and its application to disease reveals a seamless transition between pure Discovery Science investigations and conventional hypothesis-testing experiments. It demonstrates that, while the methods and goals of Discovery Science and hypothesis-testing science are quite distinct, these modes are complementary, not opposed to each other. There is one last link between Discovery Science and hypothesis-based science that I want to bring out before leaving the subject.
4. D.2.b Discovery Science and the Implicit Hypothesis
I've quoted Ramon y Cajal's comment that “No one searches without a plan,”41 and it's very instructive; a plan often depends on informal assumptions. Say you're wandering around looking for your apartment keys; even if you have “no idea” where you could have left them, you probably wouldn't look inside the box of cereal that you had for breakfast. You'd probably assume that, though perhaps forgetful, you're not yet completely out of it, and there is no way that you'd have put the keys there. Discovery Science is informed by substantive, deep implicit hypotheses of this kind. In their selection of methods and read-outs, Discovery Scientists reveal what they believe to be the most important features of nature to study.
In the early days of molecular biology researchers spent a lot of effort counting genes because they thought that genes alone determined a species' biology. It was an article of faith (i.e., a deep implicit hypothesis) that highly sophisticated animals would have many more genes than simple ones; it was an ostensibly reasonable hypothesis that made a straightforward prediction that turned out to be false.
Initial calculations suggested that, given their quantity of DNA and an assumed average size of a coding gene (which carries the instructions for—“codes for”—how to produce proteins), humans would have 50,000-140,000 genes.42 In fact, it now appears that each of us has about 20,000 genes43; that is, roughly the same number as a mouse. Surprisingly, the pool-dwelling water flea, Daphnia pulex, has about 31,000 genes,44 which, to put the situation in perspective, means that a tiny crustacean, about 1 mm in length, that expends most of its energy avoiding predators during the day and eating phytoplankton at night, has about 50% more genes than Albert Einstein did. The hypothesis that the number of genes alone determines an organism's biology is false, and the falsification immediately stimulated other investigators to wonder what was going on with the quantity of our DNA that was supposed to be making up all those other genes?
One hypothesis is that we have a large amount of non-coding DNA; up to 98% of total DNA in humans might not be part of identified genes. It could be “junk DNA,” a by-product of spontaneous molecular duplication with no biological function,45 or it could be part of the system of gene regulation. In any case, the gulf between Einstein and a mouse or a water flea may pertain to the amounts and functions of non-coding DNA, rather than to the genes themselves. The episode of gene counting is a prime example of how the implicit testing of deep hypotheses underlying a pure Discovery Science spawns new discoveries and new hypotheses to explain them.
4. D.2.C You’re Not Necessarily Doing Discovery Science Just Because You Don't Have a Hypothesis
The prominence and success of Discovery Science projects like the Human Genome Project have had some unfortunate consequences. My experience in reviewing research papers and grant applications suggests that the label “Discovery Science” is occasionally pasted onto poorly organized and incompletely thought out hypothesis-based science. It is unclear whether the authors of these productions wanted to associate their work with a popular trend, whether they believed that they were genuinely doing Discovery Science or, maybe, whether they even knew what Discovery Science was. Whatever the explanation, the result was typically an unfocused publication or application that rambled from one topic to another. Science has plenty of room for trying out hunches to see if anything turns up or doing pilot, exploratory experiments. I suspect that reserving the designation “Discovery Science” for thorough, focused investigations bent on pure discovery with the aim of producing a novel database would go long way toward clarifying scientific communications and policies.
4.