Econometric issues I: Alternative data structures
Our discussion of growth econometrics now shifts from general issues of hypothesis testing and model specification to explore specific econometric issues that arise in the estimation of growth models.
This section reviews econometric issues that arise for the different types of data structures that appear in growth analyses. By data structures, we refer to features such as whether the data are observed in cross-section, time series, or panel as well as to whether particular data series are conceptualized as endogenous or exogenous. At the risk of stating the obvious, choices of method involve significant trade-offs, which depend partly on statistical considerations and partly on the economic context. This means that attempts at universal prescriptions are misguided, and we will try to show the desirability of matching techniques to the economic question at hand.One example, to be discussed further below, would be the choice between panel data methods and the estimation of separate time series regressions for each country. The use of panel data is likely to increase efficiency and allow richer models to be estimated, but at the expense of potentially serious biases if the parameter homogeneity assumptions are incorrect. This trade-off between robustness and efficiency is another running theme of our survey. The scientific solution would be to base the choice of estimation method on a context-specific loss function, but this is clearly a difficult task, and in practice more subjective decisions are involved.
This section has four main elements. Section 6.1 examines econometric issues that arise in the use of time series data to study growth, emphasizing some of the drawbacks of this approach. Section 6.2 discusses the many issues that arise when panel data are employed, an increasingly popular approach to growth questions. We consider the estimation of dynamic models in the presence of fixed effects, and alternatives to standard procedures.
Section 6.3 describes another increasingly popular approach, namely the use of “event studies” to analyze growth behavior, based on studying responses to major shocks such as policy reforms. Section 6.4 examines endogeneity and the use of instrumental variables. We argue that the use of instrumental variables in growth contexts is more problematic than is often appreciated and suggest the importance of combining instrumental variable choice with a systematic approach to model selection.6.1. Time series approaches
At first glance, the most natural way to understand growth would be to examine time series data for each country in isolation. As we saw previously, growth varies substantially overtime, and countries experience distinct events that contribute to this variation, such as changes in government and in economic policy.
In practice a time series approach runs into substantial difficulties. One key constraint is the available data. For many developing countries, some of the most important data are only available on an annual basis, with limited coverage before the 1960s. Moreover, the listing of annual data in widely used sources and online databases can be misleading, because some key variables are measured less frequently. For example, population figures are often based primarily on census data, while measures of average educational attainment are often constructed by interpolating between census observations using school enrollments. When examining published data, it is not always clear where this kind of interpolation has been used. The true extent of information in the time series variation may be less than appears at first glance, and conventional standard errors on parameter estimates will be misleading when interpolated data are used.
Even where reliable data are available, some key growth determinants display relatively little time variation, a point that has been emphasized by Easterly et al. (1993), Easterly (2001) and Pritchett (2000a).
Theredoexist other variables that appear to show significant variation, but this variation may not correspond to the concept the researcher has in mind. An example would be political stability. Since Barro (1991), researchers have sometimes used the incidence of political revolutions and coups as a measure of political instability. The interpretation of such an index clearly varies depending on the length of the time period used to construct it. If the hypothesis of interest relates to underlying political uncertainty (say, the ex-ante probability of a transfer of power) then the observations on political instability would need to be averaged over a long time period. The variation in political instability at shorter horizons only casts light on a different hypothesis, namely the direct impact of revolutions and coups.There are other significant problems with the time series approach. The hypotheses of most interest to growth theorists are mainly about the evolution of potential output, not deviations from potential output such as business cycles and output collapses. Since measured output is a noisy indicator of potential output, it is easy for the econometric modeling of a growth process to be contaminated by business cycle dynamics. A simple way to illustrate this would be to consider what happens if measured log output is equal to the log of potential output plus a random error. If log output is trend stationary, this is a classical measurement error problem. When lags of output or the growth rate are used as explanatory variables, the parameter estimates will be inconsistent.
Such problems are likely to be even more serious in developing countries, where large slumps or crises are not uncommon, and output may deviate for long periods from any previous structural trend [Pritchett (2000a)]. We have already seen the extent to which output behaves very differently in developing countries compared to OECD members, and a major collapse in output is not a rare event.
There may be no underlying trend in the sense commonly understood, and conventional time series methods should be applied with caution. Some techniques that are widely used in the literature on business cycles in developed countries, such as the Hodrick-Prescott filter, will often be inappropriate in the context of developing countries.The problem of short-run output instability extends further. It is easy to construct examples where the difference between observed output and potential output is correlated with variables that move up and down at high frequencies, with inflation being one obvious example. This means that time series studies of inflation and growth based on observed output will find it hard to isolate reliably an effect of inflation on potential output; for further discussion see Temple (2000a). When considerations like these are combined with the paucity of the available data, it appears a hard task to learn about long-term growth using time series regressions, especially when developing countries are the main focus of interest.
Nevertheless, despite these problems, there are some hypotheses for which time series variation can be informative. We have already seen the gains from time series approaches to convergence issues. Jones (1995) and Kocherlakota and Yi (1997) show how time series models can be used to discriminate between different growth theories. To take the simplest example, the AK model of growth predicts that the growth rate will be a function of the share of investment in GDP. Jones points out that investment rates have trended upwards in many OECD countries, with no corresponding increase in growth rates. Although this might be explained by offsetting changes in other growth determinants, it does provide evidence against simple versions of the AK model.
Jones (1995) and Kocherlakota and Yi (1997) develop a statistical test of endogenous growth models based on regressing growth on lagged growth and a lagged policy variable (or the lagged investment rate, as in Jones).
Exogenous growth models predict that the coefficients on the lagged policy variable should sum to zero, indicating no long-run effect of permanent changes in this variable on the growth rate. In contrast, some endogenous growth models imply that the sum of coefficients should be non-zero. A simple time series regression then provides a direct test of the predictions of these models. More formally, as in Jones (1995), for a given country i one can investigate a dynamic relationship for the growth rate γi,t whereγi,t — A(L)Yi,t-1 + B(L)zi,t + εi,t, (58)
where z is the policy variable or growth determinant of interest, and A(L) and B(L) are lag polynomials assumed to be compatible with stationarity. The hypothesis of interest is whether B(1) — 0. If the sum of the coefficients in the lag polynomial B(L) is significantly different from zero, this implies that a permanent change in the variable z will affect the growth rate indefinitely. As Jones (1995) explicitly discusses, this test is best seen as indicating whether a policy change affects growth over a long horizon, rather than firmly identifying or rejecting the presence of a long-run growth effect in the theoretical sense of that term. The theoretical conditions under which policy variables affect the long-run growth rate are remarkably strict, and many endogenous growth models are best seen as new theories of potentially sizeable level effects.[355]
This approach is closely related to Granger-causality testing, where the hypothesis of interest would be the explanatory power of lags of zi,t for γi,t conditional on lagged values of. Blomstrom, Lipsey and Zejan (1996) carry out Granger-causality tests for investment and growth using panel data with five-year subperiods. They find strong evidence that lagged growth rates have explanatory power for investment rates, but much weaker evidence for causality in the more conventional direction from investment to growth.
Hence, the partial correlation between growth and investment found in many cross-section studies may not reflect a causal effect of investment. In a similar vein, Campos and Nugent (2002) find that, once Granger-causality tests are applied, the evidence that political instability affects growth may be weaker than usually believed.The motivation for these two studies, and others like them, is that evidence of temporal precedence helps to build a case that one variable is influenced by another. When this idea is extended to panels, an underlying assumption is that timing patterns and effects will be similar across units (countries or regions). Potential heterogeneity has sometimes been acknowledged, as in the observation of Campos and Nugent (2002) that their results are heavily influenced by the African countries in the sample. The potential importance of these factors is also established in Binder and Brock (2004) who, by using panel methods to allow for heterogeneity in country-specific dynamics, find feedbacks from investment to growth beyond those that appear in Blomstrom, Lipsey and Zejan (1996).
A second issue is more technical. Since testing for Granger-causality using panel data requires a dynamic model, the use of a standard fixed effects (within groups) estimator is likely to be inappropriate when individual effects are present. We discuss this further in Section 6.2 below. One potential solution is the use of instrumental variable procedures, as in Campos and Nugent (2002). In the context of investment and growth, a comprehensive examination of the associated econometric issues has been carried out by Bond, Leblebicioglu and Schiantarelli (2004). Their work shows that these issues are more than technicalities: unlike Blomstrom, Lipsey and Zejan (1996), they find strong evidence that investment has a causal effect on growth.
A familiar objection to the more ambitious interpretations of Granger-causality is that much economic behavior is forward-looking [see, for example, Klenow and Rodriguez- Clare (1997b)]. The movements of stock markets are one instance where temporal sequences can be misleading about causality. Similarly, when entrepreneurs or governments invest heavily in infrastructure projects, or when unusually high inflows of foreign direct investment are observed, the fact that such investments precede strong growth does not establish a causal effect.
6.2. Panel data
As we emphasized above, the prospects for reliable generalizations in empirical growth research are often constrained by the limited number of countries available. This constraint makes parameter estimates imprecise, and also limits the extent to which researchers can apply more sophisticated methods, such as semiparametric estimators.
A natural response to this constraint is to use the within-country variation to multiply the number of observations. Using different episodes within the same country is ultimately the only practical substitute for somehow increasing the number of countries. To the extent that important variables change over time, this appears the most promising way to sidestep many of the problems that face growth researchers. Moreover, as the years pass and more data become available, the prospects for informative work of this kind can only improve.
We first discuss the implementation and advantages of panel data estimators in more detail, and then some of the technical issues that arise in the context of growth. Perhaps not surprisingly, these methods introduce a set of problems of their own, and should not be regarded as a panacea. Too often, panel data results are interpreted without sufficient care and risk leading researchers astray. In particular, we highlight the care needed in interpreting estimates based on fixed effects.
We will use T to denote the number of time series observations in a panel of N countries or regions. At first sight, T should be relatively high in this context, because of the availability of annual data. But the concerns about time series analysis raised above continue to apply. Important variables are either measured at infrequent intervals, or show little year-to-year variation that can be used to identify their effects. Moreover, variation in growth rates at annual frequencies may give very misleading answers about the longer-term growth process. For this reason, most panel data studies in the growth field have averaged data over five or ten year periods. Given the lack of data before 1960, this implies that growth panels not only have relatively few cross-sectional units (the number of countries employed is often between 50 and 100) but also very low values of T, often 5 or 6 at most.[356]
Most empirical growth models estimated using panel data are based on the hypothesis of conditional convergence, namely that countries converge to parallel equilibrium growth paths, the levels of which are a function of a few variables. A corollary is that an equation for growth (essentially the first difference of log output) should contain some dynamics in lagged output. In this case, the growth equation can be rewritten as a dynamic panel data model in which current output is regressed on controls and lagged output, as in Islam (1995). In statistical terms this is the same model, the only difference of interpretation being that the coefficient on initial output (originally β) is now 1 + β:
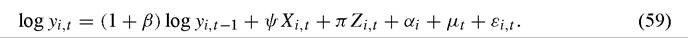
This regression is a general panel analog to the cross-section regression (18). In this formulation, αi is a country-specific effect and μt is a time-specific effect. The inclusion of time-specific effects is important in the growth context, not least because the means of the log output series will typically increase over time, given productivity growth at the world level.
Inclusion of a country-specific effect allows permanent differences in the level of income between countries that are not captured by Xgt or Ztg. In principle, one can
also allow the parameters 1 + β, ψ, and π to differ across i; Lee, Pesaran and Smith (1997, 1998) do this for the coefficients for log yi,t-1 and a linear time trend (the latter allowing for steady-state differences in the rate of technological change, corresponding to non-parallel growth paths in the steady state).
The vast majority of panel data growth studies use a fixed effects (within-group) estimator rather than a random effects estimator. Standard random effects estimators require that the individual effects αi are distributed independently of the explanatory variables, and this requirement is clearly violated for a dynamic panel such as (59) by construction, given the dependence of log yi,t-1 on αi.
Given the popularity of fixed effects estimators, it is important to understand how these estimators work. In a fixed effects regression there is a full set of country-specific intercepts, one for each country, and inference proceeds conditional on the particular countries observed (a natural choice in this context). Identification of the slope parameters, usually constrained to be the same across countries, relies on variation over time within each country. The “between” variation, namely the variation across countries in the long-run averages of the variables, is not used.
The key strength of this method, familiar from the microeconometric literature, is the ability to address one form of unobserved heterogeneity: any omitted variables that are constant over time will not bias the estimates, even if the omitted variables are correlated with the explanatory variables. Intuitively, the country-specific intercepts can be seen as picking up the combined effects of all such variables. This is the usual motivation for using fixed effects in the growth context, especially in estimating conditional convergence regressions, as is further discussed in Islam (1995), Caselli, Esquivel and Lefort (1996) and Temple (1999). A particular motivation for the use of fixed effects arises from the Mankiw, Romer and Weil (1992) implementation of the Solow model. As discussion in Section 3, their version of the model implies that one determinant of the level of the steady-state growth path is the initial level of efficiency (A^0) and cross-section heterogeneity in it should usually be regarded as unobservable, cf. Equation (15). Islam (1995) explicitly develops a specification in which this term is treated as a fixed effect, while world growth and common shocks are incorporated using time-specific effects.
The use of panel data methods to address unobserved heterogeneity can bring substantial gains in robustness, but is not without costs. The fixed-effects identification strategy cannot be applied in all contexts. Sometimes a variable of interest is measured at only one point in time. Even where variables are measured at more frequent intervals, some are highly persistent, in which case the within-country variation is unlikely to be informative. At one extreme, some explanatory variables of interest are essentially fixed factors, like geographic characteristics or ethnolinguistic diversity. Here the only available variation is “between-country”, and empirical work will have to be based on cross-sections or pooled cross-section time-series. Alternatively a two-stage hybrid of these methods can be used, in which a panel data estimator is used to obtain estimates of the fixed effects, which are then explicitly modeled in a second stage as in Hoeffler (2002). As we discuss further below, an important direction for future panel data work may be the analysis of the information content of country-specific effects.
A common failing of panel data studies based on within-country variation is that researchers do not pay enough attention to the dynamics of adjustment. There are many panel data papers on human capital and growth that test only whether a change in school enrollment or years of schooling has an immediate effect on aggregate productivity, which seems an implausible hypothesis. Another example, given by Pritchett (2000a), is the use of panels to study inequality and growth. All too often, changes in the distribution of income are implicitly expected to have an immediate impact on growth. Yet many of the relevant theoretical papers highlight long-run effects, and there is a strong presumption that much of the short-run variation in measures of inequality is due to measurement error. In these circumstances, it is hard to see how the available within-country variation can shed much useful light.
There is also a more general problem. Since the fixed effects estimator ignores the between-country variation, the reduction in bias typically comes at the expense of higher standard errors. Another reason for imprecision is that either of the devices used to eliminate the country-specific intercepts - the within-groups transformation or first- differencing - will tend to exacerbate the effect of measurement error.[357] As a result, it is common for researchers using panel data models with fixed effects, especially in the context of small T, to obtain imprecise sets of parameter estimates.
Giventhe potentially unattractive trade-off between robustness and efficiency, Barro (1997), Temple (1999), Pritchett (2000a) and Wacziarg (2002) all argue that the use of fixed effects in empirical growth models has to be approached with care. The price of eliminating the misleading component of the between variation - namely, the variation due to unobserved heterogeneity - is that all the between variation is lost.
There are alternative ways to reveal this point, but consider the random effects GLS estimator of the slope parameters, which will be more efficient than the within-country estimator for small T when the random-effects assumptions are appropriate. This GLS estimator can be written as a matrix-weighted average of the within-country estimator and the between-country estimator, which is based on averaging the data over time and then estimating a simple cross-section regression by OLS.[358] The weights on the two sets of parameter estimates are the inverses of their respective variances. The corollary of high standard errors using within-country estimation, indicating that the within-country variation is relatively uninformative, is that random effects estimates based on a panel of five-yearly averages are very similar to OLS estimates based on thirty-year averages [Wacziarg (2002)]. Informally, the random effects estimator sees the between-country variation as offering the greatest scope for identifying the parameters.[359]
This should not be surprising: growth episodes within countries inevitably look a great deal more alike than growth episodes across countries, and therefore offer less identifying variation. Restricting the analysis to the within variation eliminates one source of bias, but immediately makes it harder to identify growth effects with any degree of precision. This general problem is discussed in Pritchett (2000a). Many of the explanatory variables currently used in growth research are either highly stable over time, or tending to trend in one direction. Educational attainment is an obvious example. Without useful identifying variation in the time series data, the within-country approach is in trouble. Moreover, growth is quite volatile at short horizons. It will typically be hard to explain this variation using predictors that show little variation over time, or that are measured with substantial errors. The result has been a number of panel data studies suggesting that a given variable “does not matter” when a more accurate interpretation is that its effect cannot be identified using the data at hand.
Some of these problems suggest a natural alternative to the within-country estimator, which is to devote more attention to modeling the heterogeneity, rather than treating it as unobserved [Temple (1999)]. To put this differently, current panel data methods treat the individual effects as nuisance parameters. As argued by Durlauf and Quah (1999) this is clearly inappropriate in the growth context. The individual effects are of fundamental interest to growth economists because they appear to be a key source of persistent income differences. This suggests that more attention should be given to modeling the heterogeneity rather than finding ways to eliminate its effects.[360]
Depending on the sources of heterogeneity, even simple recommendations, such as including a complete set of regional dummies, can help to alleviate the biases associated with omitted variables. More than a decade of growth research has identified a host of fixed factors that could be used to substitute for country-specific intercepts. A growth model that includes these variables can still exploit the panel structure of the data, and overall this approach has clear advantages in both statistical and economic terms. It means that the between variation is retained, rather than entirely thrown away, while the explicit modeling of the country-specific effects is directly informative about the sources of persistent income and growth differences.
In practice, the literature has focused on another aspect of using panel data estimators to investigate growth. Nickell (1981) showed that within-groups estimates of a dynamic panel data model can be badly biased for small T, even as N goes to infinity. The direction of this bias is such that, in a growth model, output appears less persistent than it should (the estimate of β is too low) and the rate of conditional convergence will be overestimated.
In other areas of economics, it has become increasingly common to avoid the within- groups estimator when estimating dynamic models. The most widely-used alternative strategy is to difference the model to eliminate the fixed effects, and then use two stage least squares or GMM to address the correlation between the differenced lagged dependent variable and the induced MA(1) error term. To see the need for instrumental variable procedures, first-difference (59) to obtain
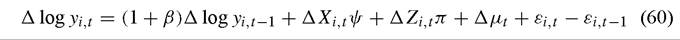
and note that (absent an unlikely error structure) the log y^t-1 component of Δ log yi,t-1 will be correlated with the ε^t-1 component of the new composite error term, as is clearly seen by considering Equation (59) lagged one period. Hence, at least one of the explanatory variables in the first-differenced equation will be correlated with the disturbances, and instrumental variable procedures are required.
Arellano and Bond (1991), building on work by Holtz-Eakin, Newey and Rosen (1988), developed the GMM approach to dynamic panels in detail, including methods suitable for unbalanced panels and specification tests. Caselli, Esquivel and Lefort (1996) applied their estimator in the growth context and, as discussed above, this approach yielded a much faster rate of conditional convergence than found in cross-section studies.
The GMM approach is typically based on using lagged levels of the series as instruments for lagged first differences. If the error terms in the levels equation (εit) are serially uncorrelated then Δ log ygt-1 can be instrumented using log yi,t-2 and earlier lagged levels (where available). This corresponds to a set of moment conditions that can be used to estimate the first-differenced equation by GMM. Bond (2002) provides an accessible introduction to this approach.
As an empirical strategy for growth research, this has some appeal, because it could alleviate biases due to measurement error and endogenous explanatory variables. In practice, many researchers are skeptical that lags are suitable instruments. It is easy to see that a variable such as educational attainment may influence output with a considerable delay, so that the exclusion of lags from the growth equation can look arbitrary. More generally, the GMM approach relies on a lack of serial correlation in the error terms of the growth equation (before differencing). Although this assumption can be tested using the methods developed in Arellano and Bond (1991), and can also be relaxed by an appropriate choice of instruments, it is nevertheless restrictive in some contexts.
Another concern is that the explanatory variables may be highly persistent, as is clearly true of output. Lagged levels can then be weak instruments for first differences, and the GMM panel data estimator is likely to be severely biased in short panels. Bond, Hoeffler and Temple (2001) illustrate this point by comparing the Caselli, Esquivel and Lefort (1996) estimates of the coefficient on lagged output with OLS and within-group estimates. Since the OLS and within-group estimates of β are biased in opposing directions then, leaving aside sampling variability and small-sample considerations, a consistent parameter estimate should lie between these two extremes [see Nerlove (1999, 2000)]. Formally, when the explanatory variables other than lagged output are strictly exogenous, we have

where β is a consistent parameter estimate, ∣3wg is the within-groups estimate and ∕3ols is the estimate from a straightforward pooled OLS regression. For the data set and model used by Caselli, Esquivel and Lefort, this large-sample prediction is not valid, which raises a question mark over the reliability of the first-differenced GMM estimates.
One device that can be informative in short panels is to make more restrictive assumptions about the initial conditions. If the observations at the start of the sample are distributed in a way that is representative of steady-state behavior, in a sense that can be made more precise, efficiency gains are possible. Assumptions about the initial conditions can be used to derive a “system” GMM estimator, of the form developed and studied by Arellano and Bover (1995) and Blundell and Bond (1998), and also discussed in Ahn and Schmidt (1995) and Hahn (1999). In this estimator, not only are lagged levels used as instruments for first differences, but lagged first differences are used as instruments for levels, which corresponds to an extra set of moment conditions.
There is some Monte Carlo evidence [Blundell and Bond (1998)] that this estimator is more robust than the Arellano-Bond method in the presence of highly persistent series. As also shown by Blundell and Bond (1998), the necessary assumptions can be seen in terms of an extra restriction, namely that the deviations of the initial values of log yyt from their long-run values are not systematically related to the individual effects.59 For simplicity, we focus on the case where there are no explanatory variables other than lagged output. The required assumption on the initial conditions is that, for all i = 1,..., N we have

where the yi are the long-run values of the log yi,t series and are therefore functions of the individual effects αi and the autoregressive parameter β. This assumption on the initial conditions ensures that

and this together with the mild assumption that the changes in the errors are uncorrelated with the individual effects, i.e.

implies T — 2 extra moment conditions of the form
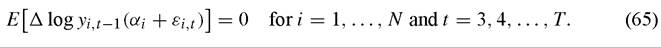
59 Note that the long-run values of log output are evolving over time when time-specific effects are included in the model.
Intuitively, as is clear from the new moment conditions, the extra assumptions ensure that the lagged first difference of the dependent variable is a valid instrument for untransformed equations in levels since it is uncorrelated with the composite error term in the levels equation. These extra moment conditions can then be combined with the more conventional conditions used in the Arellano-Bond method. This builds in some insurance against weak identification, because if the series are persistent and lagged levels are weak instruments for first differences, it may still be the case that lagged first differences have some explanatory power for levels.[361]
In principle, the validity of the restrictions on the initial conditions can be tested using the incremental Sargan statistic (or C statistic) associated with the additional moment conditions. Yet the validity of the restriction should arguably be evaluated in wider terms, based on some knowledge of the historical forces giving rise to the observed initial conditions. This point - that key statistical assumptions should not always be evaluated only in statistical terms - is one that we will return to later.
Alternatives to GMM have been proposed. Kiviet (1995, 1999) derives an analytical approximation to the Nickell bias that can be used to construct a bias-adjusted within- country estimator for dynamic panels. The simulation evidence reported in Judson and Owen (1999) and Bun and Kiviet (2001) suggests that this estimator performs well relative to standard alternatives when N and T are small. One minor limitation is that it cannot yet be applied to an unbalanced panel. A more serious limitation, relative to GMM, is that it does not address the possible correlation between the explanatory variables and the disturbances due to simultaneity and measurement error. Nevertheless, for researchers determined to use fixed effects estimation, there is a clear case for implementing this bias adjustment, at least as a complement to other methods.
A further issue that arises when estimating dynamic panel data models is that of parameter heterogeneity. If a slope parameter such as β varies across countries, and the explanatory variable is serially correlated, this will induce serial correlation in the error term. If we focus on a simple case where a researcher wrongly assumes βi = β for all i = 1,..., N then the error process for a given country will contain a component that resembles (βi - β) log yi,t-1. Hence there is serial correlation in the errors, given the persistence of output. The estimates of a dynamic panel data model will be inconsistent even if GMM methods are applied.
This problem was analyzed in more general terms by Robertson and Symons (1992) and Pesaran and Smith (1995) and has been explored in great depth for the growth context by Lee, Pesaran and Smith (1997, 1998). Since an absence of serial correlation in the disturbances is usually a critical assumption for the GMM approach, parameter heterogeneity can be a serious concern. Some of the possible solutions, such as regressions applied to single time series, or the pooled mean group estimator developed by Pesaran, Shin and Smith (1999), have limitations in studying growth for reasons already discussed. An alternative solution is to split the sample into groups that are more likely to share similar parameter values. Groupings by regional location or level of development are a natural starting point.
Perhaps the state of the art in analyzing growth using panel data and allowing for parameter heterogeneity is represented by Phillips and Sul (2003). They allow for heterogeneity in parameters not only across countries, but also over time. Temporal heterogeneity is rarely investigated in panel studies, but may be important, especially if observed growth patterns combine transitional dynamics towards a country’s steady state with fluctuations around that steady-state. Phillips and Sul find some evidence of convergence towards steady states for OECD economies as well as US regions.
We close our discussion of panel data approaches by noting some unresolved issues in their application. It is important to be aware how panel data methods change the substantive interpretation of regression results, and care is needed when moving between the general forms of the estimators and the economic hypotheses under study. Relevant examples occur in analyses of β-convergence. If one finds β-convergence in a panel study having allowed for fixed effects, the interpretation of this finding is very different than if one finds evidence of convergence in the absence of fixed effects. Specifically, the presence of fixed effects represents an immediate violation of our convergence definitions (20) or (22) as different economies must exhibit steady-state differences in per capita income regardless of whether they have identical saving rates and population growth rates.[362] Fixed effects may even control for the presence of unmodelled determinants of steady state growth, an identification problem analogous to the one that was previously discussed in the context of interpreting the control variables Z in Equations (17) and (18) above. Similarly, allowing for differences in time trends for per capita output, as done in Lee, Pesaran and Smith (1997, 1998) means that the finding of extremely rapid β -convergence is consistent with long-run divergence of per capita output across the economies they study; the long-run balanced growth paths are no longer parallel. In an interesting exchange, Lee, Pesaran and Smith (1998) criticize Islam (1995) for failing to allow for different time trends across countries. In response, Islam (1998) argues that Lee, Pesaran and Smith are assessing an economically uninteresting form of convergence when they allow for trend differences. This debate is an excellent example of the issues of interpretation that are raised in moving between specific economic hypotheses and more general statistical models.
One drawback of many current panel studies is that the construction of the time series observations can appear arbitrary. There is no inherent reason why 5 or 10 years represent natural spans over which to average observations. Similarly, there is arbitrariness with respect to which time periods are aggregated. A useful endeavor would be the development of tools to ensure that panel findings are robust with respect to the assumptions employed in creating the panel from the raw data.
More fundamentally, the empirical growth literature has not fully addressed the question of the appropriate time horizons over which growth models should be assessed. For example, it remains unclear when business cycle considerations (or instances of output collapses) may be safely ignored when modeling the growth process. While cross-section studies that examine growth over 30-40 year periods might be exempt from this consideration, it is less clear that panel studies employing 5-year averages are genuinely informative about medium-run growth dynamics.
6.3. Event study approaches
Although we have focused on the limitations of panel data methods, it is clear that the prospects for informative work of this kind should improve over time. The addition of further time periods is valuable in itself, and the history of developing countries in the 1980s and 1990s offers various events that introduce richer time series variation into the data. These events include waves of democratization, macroeconomic stabilization, financial liberalization, and trade liberalization, and panel data methods can be used to investigate their unfolding consequences for growth.
An alternative approach has become popular, and proceeds in a similar way to event studies in the empirical finance literature. In event studies, researchers look for systematic changes in asset returns after a discrete event, such as a profits warning. In fields outside finance, before-and-after studies like this have proved an informative way to gauge the effects of devaluations [see Pritchett (2000a) for references], of inflation stabilization [Easterly (1996)] and the consequences of the debt crisis for investment, as in Warner (1992).
Pritchett (2000a) argues that there is a great deal of scope for studying the growth impact of major events and policy changes in a similar way. The obvious approach is to study the time paths of variables such as output growth, investment and TFP growth, examined before and after such events. In empirical growth research, Henry (2000, 2003) has applied this form of analysis to the effects of stock market liberalization on investment and growth, Giavazzi and Tabellini (2004) have considered economic and political liberalizations, while Wacziarg and Welch (2003) have studied the effects of trade liberalization. Depending on the context, one can also study the response of other variables in a way that is informative about the channels of influence. For example, in the case of trade liberalization, it is natural to study the response of the trade share, as in the work of Wacziarg and Welch.
The rigor of this method should not be overplayed. As with any other approach to empirical growth, one has to be cautious about inferring a causal effect. This is clear from exploring the analogy with treatment effects, a focus of recent research in microeconometrics and labor economics.[363] In the study of growth, the treatments - such as democratization - are clearly not exogenously assigned, but are events that have arisen endogenously. Moreover, the treatment effects will be heterogeneous and could depend, for example, on whether a policy change is seen as temporary or permanent [Pritchett (2000a)]. In these circumstances, the ability to quantify even an average treatment effect is strongly circumscribed. It may be possible to identify the direction of effects, and here the limited number of observations does have one advantage. With a small number of cases to examine, it is easy for the researcher to present a graphical analysis that allows readers to gauge the extent of heterogeneity in responses, and the overall pattern. At the very least, this offers a useful complement to regression-based methods.
6.4. Endogeneity and instrumental variables
A final set of data-based issues concerns the identification of instrumental variables in cross-section and time series contexts. An obvious and frequent criticism of growth regressions is that they do little to establish directions of causation. At one level, there is the standard problem that two variables may be correlated but jointly determined by a third. It is very easy to construct growth examples. Variables such as growth and political stability could be seen as jointly determined equilibrium outcomes associated with, say, a particular set of institutions. In this light, a correlation between growth and political stability, even if robust in statistical terms, does not appear especially informative about the structural determinants of growth.
There are many instances in growth research when explanatory variables are clearly endogenously determined (in the economic, not the statistical sense). The most familiar example would be a regression that relates growth to the ratio of investment to GDP. This may tell us that the investment share and growth are associated, but stops short of identifying a causal effect. Even if we are confident that a change in investment would affect growth, in a sense this just pushes the relevant question further back, to an understanding of what determines investment.
When variables are endogenously determined in the economic sense, there is also a strong chance that they will be endogenous in the technical sense, namely correlated with the disturbances in the structural equation for growth. To give an example, consider what happens if political instability lowers growth, but slower economic growth feeds back into political instability. The estimated regression coefficient will tend to conflate these two effects and will be an inconsistent estimate of the causal effect of instability.[364]
Views on the importance of these considerations differ greatly. One position is that the whole growth research project effectively capsizes before it has even begun, but Mankiw (1995) and Wacziarg (2002) have suggested an alternative view. According to them, one should accept that reliable causal statements are almost impossible to make, but use the partial correlations of the growth literature to rule out some possible hypotheses about the world. Wacziarg uses the example of the negative partial correlation between corruption and growth found by Mauro (1995). Even if shown to be robust, this correlation does not establish that somehow reducing corruption will be followed by higher growth rates. But it does make it harder to believe some of the earlier suggestions, rarely based on evidence, that corruption could be actively beneficial.
One approach is to model as many as possible of the variables that are endogenously determined. A leading example is Tavares and Wacziarg (2001), who estimate structural equations for various channels through which democracy could influence development. In their analysis, democracy affects growth via factors such as its effect on human capital accumulation, physical capital accumulation, inequality and government expenditures. They conclude the net effect of democracy on growth is slightly negative, despite the positive contributions that are made from the role of democracy in promoting greater human capital and reduced inequality.
This approach has some important advantages in both economic and statistical terms. It can be informative about underlying mechanisms in a way that much empirical growth research is not. From a purely statistical perspective, if the structural equations are estimated jointly by methods such as three stage least squares or full information maximum likelihood, this is likely to bring efficiency gains. That said, systems estimation is not necessarily the best route: it has the important disadvantage that specification errors in one of the structural equations could contaminate the estimates obtained for the others.
The most common response to the endogeneity of growth determinants has been the application of instrumental variable procedures to a single structural equation, with growth as the dependent variable. As mentioned in Section 4, two growth studies that employ instrumental variables estimators based on lagged explanatory variables are Barro and Lee (1994) and Caselli, Esquivel and Lefort (1996). Appendices C and D describe a wide range of other instrumental variables that have been proposed for the Solow variables and other growth determinants respectively, where the focus has been on the endogeneity of particular variables. The variety of instruments that have been proposed illustrates that it is relatively straightforward to find an instrument that is correlated with the endogenous explanatory variable(s).
This apparent success may be illusory. In our view, the belief that it is easy to identify valid instrumental variables in the growth context is deeply mistaken. We regard many applications of instrumental variable procedures in the empirical growth literature to be undermined by the failure to address properly the question of whether these instruments are valid, i.e., whether they may be plausibly argued to be uncorrelated with the error term in a growth regression. When the instrument is invalid, instrumental variables estimates will of course be inconsistent. Not enough is currently known about the consequences of “small” departures from validity, but it is certainly possible to envisage circumstances under which ordinary least squares would be preferable to instrumental variables on, say, a mean square error criterion.
A common misunderstanding, perhaps based on confusing the economic and statistical versions of “exogeneity”, is that predetermined variables, such as geographical characteristics, are inevitably strong candidates for instruments. There is, however, nothing in the predetermined nature of these variables to ensure either that they are not direct growth determinants or that they are uncorrelated with omitted growth determinants. Even if we take the extreme (from the perspective of being predetermined) example of geographic characteristics, there are many channels through which these could affect growth, and therefore many ways in which they could be correlated with the disturbances in a growth model. Brock and Durlauf (2001a) use this type of reasoning to make a very general critique of the use of instrumental variables in growth economics, basing it on the notion of theory open-endedness that we have described earlier. Since growth theories are mutually compatible, the validity of an instrument requires a positive argument that it cannot be a direct growth determinant or correlated with an omitted growth determinant. For many of the instrumental variables that have been proposed, this is clearly not the case.
Discussions of the validity of instruments inevitably suffer from some degree of imprecision because of the need to make qualitative and subjective judgments. When one researcher claims that it is implausible that a given instrument is valid, unless this claim is made on the basis of a joint model of the instruments and the variable of original interest, another researcher can always simply reject the assertion as unpersuasive. To be clear, this element of subjectivity does not mean that arguments about validity are pointless.[365] Rather, one must recognize that not all statistical questions can be adjudicated on the basis of mathematical analysis.
To see how different instruments might be assigned different levels of plausibility, we consider two examples. Brock and Durlauf (2001a) single out Frankel and Romer’s (1999) geographic instruments as an example where instrument validity appears suspect as such variables are likely correlated with features of a country’s economic, political, legal, and social institutions.[366] In our view, the large body of theoretical and empirical evidence on the role of institutions on growth, as well as even a cursory reading of history, renders the orthogonality assumptions required to use the instruments questionable.[367] For example, it is a standard historical claim that the fact that Great Britain is an island had important implications for its political development. While Frankel (2003) suggests that this worry is contrived, the argument against instrument validity flows quite naturally from modern growth theory and the many possible ways in which geographic characteristics such as remoteness could influence development.
As an example where instrument validity may be more plausible, consider Cook (2002a). He employs measures of damage caused by World War II as instruments for various growth regressors such as savings rates. The validity of Cook’s instruments again relies on the orthogonality of World War II damage with omitted postwar growth determinants. It may be that levels of wartime damage had consequences for post-War growth performance in other respects (such as institutional change) but this argument is perhaps less straightforward than in the case of geographic characteristics.
To be clear, this discussion is nowhere near sufficient to conclude that Frankel and Romer’s instruments are invalid whereas Cook’s are valid. Rather our point is that conclusions concerning the relative plausibility of one set of instruments versus another need to rest on explicit arguments. It is not enough to appeal to a variable being predetermined, because this does not ensure that it is uncorrelated with the disturbances in the structural equation being estimated. A key implication of our discussion is that historical information has a vital role to play in facilitating formal growth analyses and evaluating exclusion restrictions.
This discussion of instrumental variables indicates another important, albeit neglected, issue in empirical growth analysis: the relationship between model specification and instrumental variable selection. One cannot discuss the validity of particular instruments independently from the choice of the specific growth determinants under study. An important outstanding research question is whether model uncertainty and instrumental variable selection can be integrated simultaneously into some of the methods we have described, including model averaging and automated model selection. The recent work of Hendry and Krolzig (2005) on automated methods includes an ambitious approach to systematic model selection for simultaneous equation models in which identifying restrictions are determined by the data.
7.