From theory to empirics: Econometrics and social capital
Having clarified the relationship between social capital and the efficiency of social exchange, we now turn to the statistical analysis of the effects of social capital. We first revisit the points raised in this section, such as the distinction between individual and aggregate efficiency effects.
We then ask whether it is possible to uncover social capital effects from the sorts of data available to social scientists. In particular, we discuss the issue of identification, that is, of whether a role for social capital can be uncovered when other types of social effects may be present.Standard practice in economics and sociology is to run regressions of some outcome of interest against a set of controls and some asserted empirical proxies for social capital. These regressions are often justified by an informal argument that the empirical proxies act as instrumental variables for the unobserved ‘true’ social capital measure. At one extreme, one finds analyses such as Furstenberg and Hughes (1995) in which the probability that an individual drops out of school is related to variables such as the presence of a father in the household or the educational aspirations of the person’s friends. In contrast, studies such as Knack and Keefer (1997) attempt to explain growth differences across entire countries using survey measures of trust.
In this section, we discuss some general econometric issues that arise in social capital studies of this type. We first examine difficulties inherent in the estimation of the benefits from social capital on the basis of individual data. These difficulties are not specific to social capital and are shared by other externalities. But they are often ignored in empirical work.
Second, we discuss the question of model specification. Inparticular, we review some requirements for treating a given social capital regression as causal.
Next, we discuss identification. In this case, we assume that a researcher has the ‘correct’ model of some outcome of interest and ask whether observational data on the phenomena will allow for the identification of a causal relationship between social capital and the outcome.The basic econometric issues associated with identifying a role for social capital may be understood in the context of cross-sections. While panel data have certain advantages, notably that they allow for the researcher to control for fixed effects across units, the conditions under which social capital effects may be identified are not qualitatively different.
4.1. Externalities and individual vs. aggregate effects
As we have discussed in Section 2, the literature on social capital is interested in externalities arising from coordination failure. Much of the empirical work on social capital seeks to identify the effect of social capital on an outcome variable of interest, say ωi. This variable of interest can be measured at the aggregate level - e.g., country growth - or at the individual level - e.g., performance of a pupil on an exam. Empirical work on social capital can thus be divided into individual and aggregate level regressions.
The first difficulty many researchers encounter is that individual returns to social capital often are poor predictors of aggregate externalities. There are two main reasons for this: fallacy of composition and free riding. A fallacy of composition arises whenever social capital pegs individuals against each other. In a situation of competition for a finite resource, the gains made by those with more social capital lead to losses for those without, relative to a situation without social capital. Free riding is the opposite situation in which aggregate social gains are larger than those appropriated by the owners of social capital. We discuss them in turn.
4.1.1. Fallacy of composition
To illustrate fallacy of composition, consider a simple job search example inspired by Granovetter’s work.
Suppose there are M job openings and N job seekers, all identical, with N > M. Suppose that employers and workers do not know each other and are matched at random. Since N > M, all positions are filled and each worker has an equal probability M/N of getting a job. Total surplus is the sum of employer and worker surplus. Since all workers are equivalent, total surplus is the same irrespective of which workers get the available jobs.Next suppose that, because of interpersonal connections, a group of workers C hears about the open positions before other workers. Further suppose that C < M. Consequently C workers get a job with probability 1. Other workers get the remaining jobs with probability (M — C)∕(N — C) which is smaller than M/N. Total surplus is unchanged since workers are equivalent. Social networks - in this case the existence of a better connected group of workers - have no effect on the efficiency of social exchange. But they have important distributional consequences, which can be measured by regressing the probability of obtaining a job on group membership. Doing so in our example would yield a coefficient of 1 — (M — C)∕(N — C) on membership in the group even though the net effect of social networks on aggregate welfare is zero. What this example illustrates is that social networks can have private returns even when they have no effect - other than distributional - on the efficiency of social exchange. Observing private returns to social networks should therefore not be construed as evidence of social capital. In our example, social networks actually generate a discriminatory outcome, which is inconsistent with equality of opportunity as conceptualized by Roemer (1998) for example.[416]
The above reasoning can be extended to situations where groups, not individuals, compete with each other. Consider, for instance, high schools competing to place their graduates at Harvard. We assume that the number of admissions in Harvard is fixed and that the university selects the students with the best grades on a standardized test.
Suppose that Coleman is right and that, because of the social capital effects of parental involvement in school affairs, students in PTA-run schools obtain better grades. As a result, they are more likely to go to Harvard than students from nonPTA schools. Whether or not this raises social welfare depends on how critical high school education is to university learning.To illustrate this point, suppose that students learn all they need to know at Harvard. The only purpose of high school education is to screen out less able students. Further assume that the minimum grade required to be admitted at Harvard is higher than the grade necessary to earn one’s degree: some applicants do not get in even though, if they did, they would earn their degree. In this case, the role of social capital is again to enable one group - students in PTA schools - preferential access to a rationed resource - admission at Harvard. The effect of social capital is distributional. Regressing the probability of admission in Harvard on social capital would yield a positive coefficient even though, in this example, the effect of social capital on the efficiency of social exchange is zero. Of course, we do not claim that the above example is an accurate depiction of the education system. The only purpose of the example is to illustrate the danger of estimating the beneficial effect of social capital by comparing individual or group outcomes according to whether or not they have social capital. Whenever social capital enables one group to displace another, a statistical comparison of the two groups is bound to overestimate the efficiency gain from social capital.
This example exposes another ambiguity of the concept of social capital. In our review of definitions of social capital, we noted that most authors associate social capital with the idea of beneficial group externalities. In the above - admittedly extreme - example, groups of students in PTA-run schools benefit from the social capital generated by their parents.
But society as a whole does not. According to our definition, there is social capital at the level of each group but not at the aggregate level. This contradiction serves to remind us that it is perilous to define a social process as necessarily having beneficial effects.4.1.2. Freeriding
It is also possible that social capital generates beneficial externalities but yields no (or few) individual returns for the holders of social capital. A case in point is when the external effects of social capital are fully captured by outsiders - i.e. individuals or groups who are outside the social networks or do not share the norms and values of the group - who do not incur the cost of generating the externality.
To see this, consider N groups of fishermen tapping the same fishing ground.[417] Without collective action, there is over-fishing. Suppose that fishing groups with better social capital enforce self-restraint - either through shared norms or through relational contracting - while others do not. Gains from self-restraint are shared among all fishermen, irrespective of whether they have social capital or not. Social capital increases aggregate social welfare but fishermen with less social capital have higher profit because they free ride: they benefit from the self-restraint of others without having to incur any cost. Regressing fish catch on social capital would result in a zero or negative coefficient on social capital even though it has a positive social return.
The externality can also be pecuniary. Keeping the fishing example, a similar result obtains if the fishing groups do not share a common fishing ground but sell their fish on the same market: social capital makes collusion to restrict supply possible since all fishermen benefit from higher fish prices.[418] To ascertain the effect of social capital, one needs to compare fishing groups who do not compete with each other by either accessing the same fishing ground or by selling fish on the same market.
What these examples demonstrate is that, in the presence of fallacy of composition or free riding, individual returns from social capital are poor indicators of aggregate returns. If social capital enables certain individuals or groups to capture rents at the expense of others (e.g., jobs in a nonclearing labor market, entry at Harvard when the entry criterion is excessive), individual returns to social capital exceed social returns, and social capital generates unequal outcomes. In contrast, if social capital generates positive externalities not fully appropriated by owners of social capital, individual returns underestimate social returns.
4.2. Model specification
4.2.1. Exchangeability
As we have noted, social capital studies have been applied to a remarkably large number of units of observation, ranging from individual farmers to countries. One natural question is whether these studies in fact use comparable observations. At an abstract level, comparability of observations is a requirement for virtually all causal studies. We raise the question in the context of social capital studies for several reasons.
First, social capital studies, particularly those that employ aggregate data, often use relatively crude sets of control variables. As a result, the residuals in the sample will contain forms of heterogeneity that call into question the placement of the observations in a common regression.
Second, social capital studies often fail to account for the reasons why different agents come to have different levels of social capital. As Durlauf (2002c) states,
... statistical analysis of social capital typically compare outcomes for individuals or aggregates who have social capital versus those who do not. These studies, in turn, typically do not incorporate a separate theory of the determinants of social capital formation, although they do often employ instrumental variables to account for the endogeneity of social capital. However, without a theory as to why one observes differences in social capital formation, one cannot have much confidence that unobserved heterogeneity is absent in the samples under study (p. 464).
Notice that this argument is more general than simply arguing that social capital is an endogenous variable. Since the groups in which individuals are organized often are endogenous, there will be various forms of sample selection that need to be accounted for in empirical work.
To see that these are more than abstract concerns, consider the regressions employed in Helliwell and Putnam (2000) to show the effects of social capital on economic growth. These authors regress regional output growth in Italy against initial output and measures of civic community, institutional performance, and citizen satisfaction. They find that these three measures explain persistent differences in regional growth rates and conclude that this supports social capital explanations of economic performance. Among the many questionable assumptions that underlie such a conclusion is the assumption that the regression they employ is using comparable objects as observations. In other words, the analysis assumes that each observation is generated by a common growth process. What must be assumed about the growth process in different regions when one includes Northern and Southern Italian regions in a regression? One answer to this question is that one must assume that given the variables included in the regression, the errors for the observations of different regions cannot be distinguished, at least from the perspective of their distributions. Put differently, one must assume that the regression is such that there is no reason to expect that the error from a particular region has a nonzero expected value, for example. But how can a regression of this crudity make such a breathtaking claim? The historical and social science literatures give any number of reasons why this assumption is false in contexts such as Italian regimes. But if the assumption is false then one cannot defend the interpretation provided by Helliwell and Putnam (2000) for their regression results.
Brock and Durlauf (2001b) argue that a way to formalize the notion of comparability is via the mathematical concept of exchangeability. We introduce this formalism as it provides a way of providing a link between the ways one thinks about data as a social scientist and the sorts of statistical assumptions that underlie regression exercises.
Suppose that for each of I observations, one has associated information Fi. This information may include factors that are quantifiable, such as the savings rate of a country, as well as factors that are not necessarily quantifiable, such as knowledge of a country’s culture. Suppose that some outcome ωi is generated by the linear model

where Zi represents that part of Fi that is controlled for in the regression. Typically, models such as (1) are interpreted as meaning that, except for differences in the value of Zi, ωi may be thought of as draws from a common distribution, which in turn means that the ηi ,s are drawn from a common distribution. Notice, however, that this notion of being drawn from a common distribution should be determined relative to the complete information set available for each observation, i.e. Fi. Hence, interpretation of (1) presupposes that having controlled for the various Zi ,s, one has no information that allows one to distinguish the residuals. Formally, the errors ηi are Fi -conditionally exchangeable, which means that
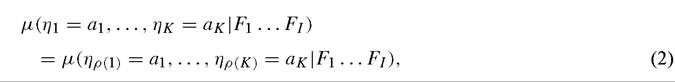
where ρ(∙) is an operator that permutes the K indices.
Exchangeability is a useful formalization because it creates a benchmark for the assessment of empirical studies. In fact, many of the standard problems that arise in regression analysis amount to exchangeability violations. For example, when a regressor is omitted from a regression, this will mean that the errors in (1) are no longer exchangeable as the distribution of a given error will depend on the distribution of the included and omitted variables. Similarly, if there is parameter heterogeneity between observations, this will imply that the distribution of a given error depends on which country it is associated with. To take a third example, self-selection can induce exchangeability violations as the errors associated with one observation may be differentiated from other differences in the implications of self-selection for the conditional expectations of the residuals. To be clear, as Brock and Durlauf (2001b) observe, exchangeability is not necessary for causally interpreting regressions. For example, heteroskedasticity in errors is an exchangeability violation, but is compatible with a structural regression interpretation. What we argue here is that good empirical practice requires that one assess whether conditional exchangeability of errors holds for the regression under study. To be more precise, we believe that a good empirical practice is to ask, for a given regression specification whether, given the information a researcher possesses about the individual observations, the researcher can justify the assumption of (2) and if not, determine whether the regression retains the interpretation the researcher wishes to place upon it.
4.2.2. Instrumental variables
As observed above, in many contexts social capital is endogenous social capital. The problem of endogeneity is obvious in many contexts; when one talks about membership in organizations, one must account for the fact that membership is a choice variable. In other cases, the endogeneity problem is more subtle. Measures of trust are often used to characterize social capital. Since trust presumably is related to trustworthiness in actual behavior, such measures will exhibit endogeneity problems as well.
Many researchers have recognized that social capital is endogenous and so have employed instrumental variables to allow for consistent estimation of parameters. Leaving aside issues of self-selection that are not often not appropriately addressed by instrumental variables approaches, the use of instrumental variables in social capital studies can be subjected to criticism. Specifically, in many social capital studies the choice of instrumental variables often appears to rely on ad hoc and untenable exogeneity assumptions.
For example, Narayan and Pritchett (1999), using village level data, argue that measures of village level trust can instrument for measures of group memberships. In their analysis social capital effects are argued to occur when one individual’s ‘associational life’ affects others in his village; measures of associational life include factors such as the number of group memberships. Since associational life may be a consumption good and thereby an increasing function of individual income, Narayan and Pritchett argue that it must be instrumented if one wants to identify how social capital causally affects income. Yet, there is little reason that such a variable is a valid instrument. As pointed out above, if trust is related to trustworthiness, as presumably is the case, then there is no reason why trustworthy behavior is any different than membership in an organization in terms of whether it is a choice variable. And without a theory of what determines trustworthy behavior, there is little hope of identifying credible instrumental variables for it in these types of regressions.
The choice of instrumental variables is often one of the most difficult problems in empirical work. In social capital contexts, the absence of explicit modeling of the process by which groups are formed and social capital created means that an empirical researcher is forced to rely on intuition and guesswork. While this does not condemn all studies using instrumental variables, we do believe that inadequate attention has been paid to justifying instrumental variables in social capital contexts.
4.2.3. Group effects versus social capital effects
A final specification issue in social capital studies concerns the question of distinguishing between social capital and other group effects. There is no shortage of reasons why group memberships influence individuals. For example, in recent models of income inequality, primary emphasis has been given to peer group effects and role model effects as influencing educational outcomes for youths. This creates a relationship between the outcomes for a given youth and the outcomes of others in his community of residence.[419] In many modern growth models, a key assumption is the presence of various types of increasing returns to scale that are produced by externalities. These types of models often take the form of positing that the productivity of a given actor depends on the human and physical capital stocks of others. From the perspective of statistical modeling, the description of individual behavior will require the incorporation of various group-level variables.
From the perspective of empirical work, the problem is simple. If one claims that a social capital effect is present for some behavior on the basis of the statistical significance of a group-level variable, this claim will not be credible unless one is able to argue that the group-level variable is capturing social capital versus some alternative group-level effect. This problem is particularly serious when social capital is endogenous, since aggregate levels of social capital are then determined by other group-level variables, which, in absence of strong prior information, presumably include whatever aggregate variables have been omitted from a regression explaining outcomes.
4.3. Identification
The question of social capital and other group effects leads to the question of identification. In this section, we assume that the model under study is correctly specified and evaluate what model parameters can be recovered from observational data. This work is developed in Durlauf (2002c), a paper which builds on early work by Manski (1993) and later work by Brock and Durlauf (2001a, 2001c) on identifying group effects in data. Ourbasic framework treats the level of social capital in a community as an endogenous variable that represents the aggregation of individual-specific social capital levels [for example, investments in individual-specific social capital as in Glaeser, Laibsonand Sacerdote (2002)]. As such, the determination of how social capital effects individuals is an example of the ‘reflection problem’ that Manski’s seminal (1993) paper characterizes; identification problems arise when one needs to distinguish the effects of the choices of others versus the characteristics of others on an individual. Identification questions when social capital is exogenous are discussed separately.
4.3.1. Individual-level data
We first consider the case where one wishes to understand the effect of social capital on some individual outcome ωi. For individual-level data, linear versions of social capital models can be expressed as follows. Suppose that each agent i is a member of some group g(i). Each individual chooses an outcome variable that is linearly dependent on some control variables. Assume these variables are of four types: an r-dimension vector of variables that are measured at the individual level, Xi; an ^-dimension vector of variables (often called contextual effects) that are measured at the group level and are predetermined at the time that choices are made, Yg(i); an individual’s expectation of the average choice of others, E(ωg(i)∖Fg(i)) [called an endogenous effect, cf. Manski (1993)], where this expectation is made conditional on some information set Fg(i); and expected social capital in the community, E(SCg(i) ∖Fg(i)). The assumption that individual behavior depends on expected rather than actual social capital does not result in any loss of generality. Similarly, our assumption that agents react to the expected behaviors and social capital levels in their group rather than the expected levels among group members other than themselves has no bearing on the analysis, cf. Brock and Durlauf (2001a, 2001c).
We assume that the Xi and Yg(i) vectors are components of the information sets from which expectations are formed; these expectations are further assumed to be rational, so we work with mathematical expectations rather than subjective beliefs. The behavioral outcome is described by
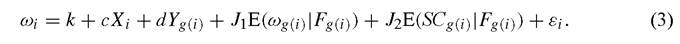
In order to close the model, it is necessary to specify how group level social capital is determined. We assume that group level social capital is the average of individual social capital levels, SCi. These levels are determined by an individual-level behavioral equation that is analogous to (3),
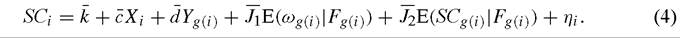
The identification problem amounts to asking whether the parameters in (3) are uniquely determined by the reduced form equations that describe ωi and SCi. In order to solve for these reduced form equations, one first applies an expectations operator to both sides of (3) and (4). For the outcome equation,
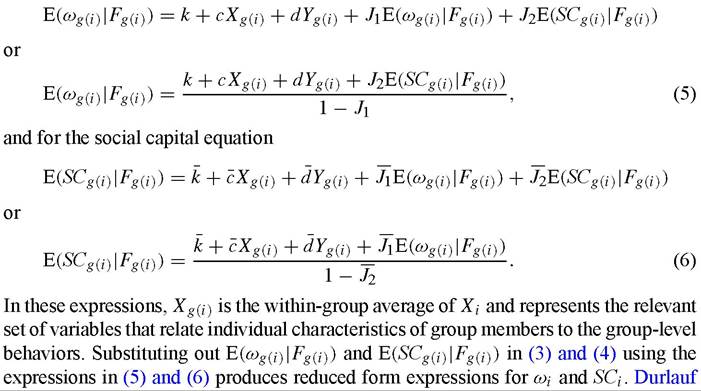
(2002c) verifies the following proposition, which describes necessary conditions for identification.
Proposition 1 (Identification in linear individual-level models with social capital). Identification of the parameters in Equation (3) requires:

What this proposition states is that identification depends critically on the relationship between the vector Xg(i) that does not appear in the behavioral Equations (3) and (4) and the vectors Xi and Yg(i) that do appear in these equations. Intuitively, the key idea is that identification of Equation (3) fails if E(ωg(i∙∙l∖Fg(i∙f) and E(SCg(i)∖Fg(i)) are linearly dependent on the otherterms in the regression, i.e. (1, Xi, Yg(i)). Each of these variables is a linear function of Yg(i) and Xg(i). So, if Xg(i) is linearly independent of these other regressors, identification may hold.
What does this theorem require in terms of empirical implementation? A key requirement is that there are at least two Xi variables whose within-group averages are not elements of Yg(i). The existence of such variables will of course depend on context. For example, one can imagine situations in which an individual’s age affects his behavior, but not the average age of others in his group. The need for such prior information illustrates how field work and qualitative studies can augment formal statistical analyses.
4.3.2. Aggregate data
A number of social capital studies employ data that are aggregated. Typically, these studies explore the average behavior of groupings which define the social environment for the individuals that comprise them. From the perspective of estimation, one can think of such models as taking within group averages of (3) and (4), so that 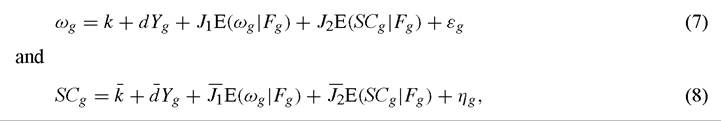 where ωg and SCg are group level averages.
where ωg and SCg are group level averages.
Necessary conditions for identification in this case are also developed in Durlauf (2002c). To characterize these conditions, let Hωg and Hsc,g denote the linear spaces spanned by those regressors Yg with nonzero coefficients in Equations (7) and (8), respectively. Let Hfc g denote that part of Hscig that is orthogonal to Hωg (i.e. the linear space formed by the orthogonal complements of any basis of Hsci g after being projected on Hωg). These spaces are used in the following proposition on identification.
Proposition 2 (Identification of social capital effects with aggregate data).
(i) Identification of the parameters in Equation (7) requires that the dimension of the linear space HSsc g is at least 2.
(ii) If Ji is known to equal 0, then identification of the parameters of Equation (7) requires that the dimension of the linear space H{C g is at least 1.
Relative to the identification condition for the individual level model, there are some important differences. specifically, in the aggregate case, one no longer has access to instrumental variables based on the averaging of individual-level variables. in order to achieve identification, it is necessary to have prior knowledge of aggregate variables that affect social capital but do not affect the aggregate outcome under study. intuitively, in the aggregate data case, one is in essence working with a standard simultaneous equations system, so cross-equation exclusion restrictions must be employed to achieve identification.
To repeat, the import of these various econometrics issues depends on the context under study, the data available to a researcher, etc. The issues raised in this section should be regarded as providing benchmarks in the assessment of empirical studies; their salience will depend on the context that is under study.
4.3.3. Identification with predetermined social capital
When social capital is predetermined, the relevant individual level equation is now
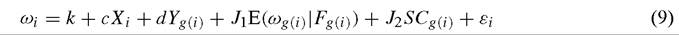
which means that social capital enters the equation in a symmetric way to the contextual effects Yg(i). Identification for models of this type has been initially studied in Manski (1993) and subsequently by Brock and Durlauf (2001a, 2001b); an identification problem still exists because of the potential multicollinearity of E(ωg(i)∖Fg(i)) with the other control variables in (9). Durlauf (2002c) provides the following necessary conditions for identification.
Proposition 3 (Identification of individual level behavioral equation with exogenous social capital). Identification of the parameters in Equation (9) requires:

However, unlike the endogenous social capital case, it may be possible to identify whether the role of social capital is nonzero even if (9) is not identified. Following an argument of Manski (1993), observe that the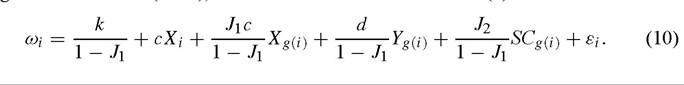 reduced form for (9) is
reduced form for (9) is
Identification of the compound parameter J2/(1 - J1) is sufficient for determining whether there is some social capital effect. Identification of this parameter requires that the social capital variable is not linearly dependent on the other variables in (10); formally [Durlauf (2002c)] verifies:
Proposition 4 (Identification of a social capital effect when social capital is exogenous). Ifthe dimension of (1, Xi, Xg(i), Yg(i), SCg(i)) exceeds that of (1, Xi, Xg(i), Yg(i)) then the presence of a social capital effect may be identified from (10).
Proposition 4 may be readily extended to the case of aggregate data; if aggregate social capital is exogenous then it is simply nothing more than an additional regressor in an aggregate outcome regression. on the other hand, if one is working with aggregate data and social capital is exogenous, then it is impossible to identify any of the model parameters. The reason is simple: there are no longer any instrumental variables available from the social capital equation to instrument E(ωg(i)∖Fg(i)), so no analog to Proposition 3 exists.
4.4. Additional issues
A number of difficulties beyond identification plague empirical work on social capital. As we have emphasized in Section 2, reliance on interpersonal relationships and networks can often be seen as a symptom that formal institutions do not work well.[420] To illustrate how this might impact statistical analysis, suppose we have data on labor markets in different countries and we seek to estimate whether the density of social networks raises the average quality of the match between workers and employers. Suppose for the sake of argument that we have a convincing measure for the average quality of the match. Regressing this measure against the density of social networks is likely to yield incorrect results if the researcher does not control for differences in formal institutions across the countries.
For instance, employment offices may play an active match-making role in some countries. Failing to control for employment offices would underestimate the effect of social capital. In fact, if employment offices channel information more efficiently than interpersonal networks and if these networks arise in response to the absence of employment offices, countries with more networks will have less efficient labor markets.
Studies of the effects of social capital on the delivery of public goods suffer from other problems as well. Earlier in this section we have argued that social capital is difficult to disentangle from other group effects. One such group effect likely to influence empirical work is the role of leadership. Community leaders often play a crucial role in fostering the creation of social capital - e.g., membership drive - that they can harness for a particular goal. Observing a relationship between social capital and the presence of a public good may be due to the presence of a third, unobserved factor: leadership. The distinction between the two effects is important for policy because good community leaders are rare and leadership is much harder to replicate than groups.
5.
More on the topic From theory to empirics: Econometrics and social capital:
- Women's Role and Social Capital
- Empirical studies of the effects of social capital
- Empirics
- Capital adequacy management
- When does social capital matter?
- Normative Bases of Torture and Capital Punishment in Islamic Law and Political Theory