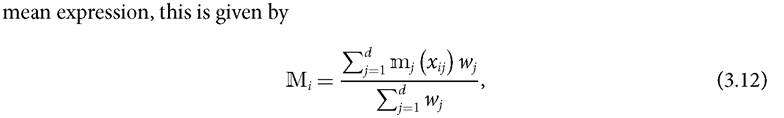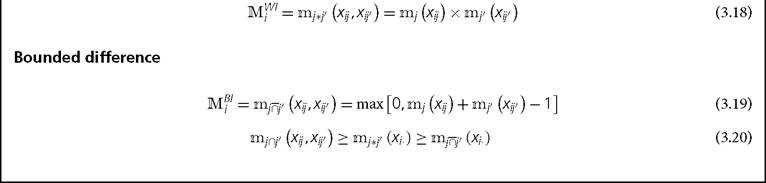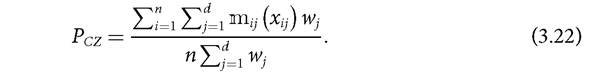Fuzzy Set Approaches
One challenge of poverty measurement is that it requires identifying who is poor. As presented in Chapter 2, such identification is traditionally accomplished using poverty lines in the unidimensional framework.
In a multidimensional counting framework, deprivation cutoffs enable us to identify who is deprived and a cross-dimensional poverty cutoff identifies who is poor. In each of these cases, a ‘crisp’ threshold dichotomizes the population into two groups that are understood to be qualitatively different, with an implicit presumption of certainty about such a distinction. Yet, intuition suggests that there might actually be considerable ambiguity in such an exercise. In fact, for example, in the unidimensional space, one might argue that being one cent above or below the income poverty line of US$1.25/day does not make any substantive difference in the person's actual situation. Similarly with ordinal data, there may be some uncertainty about the cutoffs distinguishing ‘safe' from ‘unsafe' water. Amartya Sen has warned about the risks of merrily ignoring such ambiguity:If an underlying idea has an essential ambiguity a precise formulation of that idea must try to capture that ambiguity rather than attempt to lose it. Even when precisely capturing an ambiguity proves to be a difficult exercise, that is not an argument for forgetting the complex nature of the concept and seeking a spuriously narrow exactness. In social investigation and measurement, it is undoubtedly more important to be vaguely right than to be precisely wrong.[104]
3.5.1 Fuzzysetpovertyapproach
It is precisely with the aim of dealing with such ambiguity that the fuzzy set theory—a technique extensively used in computer science and mathematics literature—was adapted for poverty measurement. The concept of fuzzy sets was first articulated by Zadeh (1965) and then developed by a large academic community, including Dubois and Prade (1980).
Beginning with the seminal work of Cerioli and Zani (1990), fuzzy sets began to be used for multidimensional as well as unidimensional poverty analysis.[105] The use of this technique in poverty analysis expanded considerably, following Chiappero-Martinetti (1994, 1996, 2000) and Cheli and Lemmi (1995), during a period of fast-emerging research on the capability approach.[106]A significant academic literature now applies the fuzzy set approach to poverty measurement. The theoretical contributions include Betti and Verma (2008), Cerioli and Zani (1990), Chakravarty (2006), Cheli and Lemmi (1995), Chiappero-Martinetti (1994, 1996, 2000), Clark and Hulme (2010), and Qizilbash (2006). Papers with comparative empirical analysis across methodologies include Amarante et al. (2010), Belhadj (2011), Belhadj and Matoussi (2010), Belhadj and Limam (2012), D'Ambrosio et al. (2011), Deutsch and Silber (2005), Lelli (2001), and Roche (2008). The context of analysis varies from countries in Europe to developing countries. Most analyses use household survey data; others employ macro data in which the country is the unit of analysis (see Baliamoune-Lutz and McGillivray 2006; Berenger and Verdier-Chouchane 2007). While most published materials are academic papers, there are also policy applications—such as a targeting method implemented for the ministry of planning in Colombia by Florez et al. (2008,2011) and a proposal for fuzzy targeting applied to Chile by Makdissi and Wodon (2004). The book edited by Lemmi and Betti (2006) presents a valuable compilation of conceptual and empirical papers on the fuzzy set approach.
Fuzzy sets extend classical set theory, on which the Venn diagrams introduced in section 3.2 are based. While in classical set theory elements either belong to a set or not, fuzzy sets allow elements to have different degrees of membership to a set. Applied to poverty measurement, a key innovation is that rather than defining a person as either belonging to the set of the poor or not (i.e.
identifying in a crisp way), the approach allows for degrees of membership to the set of the poor or deprived. Fuzzy set theorists believe that poverty is conceptually a ‘vague predicate' and that the fuzzy set approach deals systematically with the vagueness and complexity of multidimensional poverty (Chiappero-Martinetti 2008; Qizilbash 2006).[107] At the time of its first implementation, the fuzzy set approach was one of the techniques aiming to deal with various dimensions and level of measures systematically. Chiappero-Martinetti (2008) argued that the fuzzy set approach offered a way to deal systematically with the complexity in the measurement of multidimensional poverty that emerges because of the need to make various choices (dimensions, weights, cutoffs, and so on).Identification of poverty status is typically clear in cases of the undeniably rich or the absolutely destitute. But there are many intermediate cases where it is not completely clear if people are poor or not.[108] This is typical of vague predicates.[109] The predicate ‘being poor' is subject to what is known as the Sorites paradox. Suppose that we take one dollar away from someone who we consider undeniably rich, say a billionaire. We would be prepared to accept that this act would not change the fact that the person is rich. Taking another dollar away would not make any difference either. If we continue repeating this act and asking the same question every time, we would always need to accept that taking one dollar away does not make the wealth level of the billionaire significantly different. However, the paradox is that if one continues repeating this action long enough, at some point we would have to accept that the billionaire is no longer a rich person and may have even become poor. Although it would be a paradox if the billionaire were rich and poor at the same time, there remains a vagueness about the exact point at which the billionaire became poor.
The fuzzy set approach addresses the intrinsic vagueness of the ‘being poor' predicate by using so-called ‘membership functions' at the identification step. Instead of setting a crisp deprivation or poverty cutoff, it defines a ‘band' where the predicate is neither true nor false. Within the poverty band, a membership function is chosen to establish the degree of certainty of the predicates ‘this person is poor' or ‘this person is deprived' in a particular dimension. A fuzzy set approach may aggregate across dimensions using fuzzy logic operators and across individuals using an aggregation function. As we will see, the fuzzy set approach has been applied with cardinal or ordinal variables.
Fuzzy set approaches have been applied mainly to deprivation cutoffs and to an overall poverty cutoff used to identify who is poor. These are sketched in the next two sections.
3.5.2 MEMBERSHIP FUNCTIONS
In a traditional crisp set, a person i is deprived in a given dimension j (among all d dimensions) by comparing her achievement in that dimension, xij, with the deprivation cutoff Zj. If the achievement is below the deprivation cutoff, the individual is considered unambiguously deprived and otherwise she is considered unambiguously non-deprived. Let mj∙ (xij) denote the membership function of individual i to the set of those deprived in dimension j, which is a function of the level of achievement of an individual i in a dimension j. In a crisp set, the membership function is given by
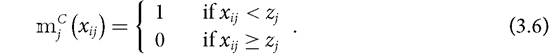
Thus each individual is either a member of the set of the deprived, in which case she is assigned a value of 1, or not a member of the set of the deprived, in which case she is assigned a value of 0.4° In the unidimensional case, such as for income or consumption poverty measurement, the individual is considered unambiguously poor or non-poor correspondingly.

Naturally, as Cerioli and Zani (1990) explain, the main challenge of this approach is selecting and justifying a particular membership function from various alternatives.[110] [111] [112] The appropriate membership function will depend on the purpose of the study and the nature of the variable (Cerioli and Zani 1990; Chiappero-Martinetti 1994,1996,2000; Cheli and Lemmi 1995). The simplest membership function for cardinal variables is a simple linear form in which the lower bound is the minimum achievement value and the upper bound is the maximum, and a linear function is used for all intermediate values (Cerioli and Zani 1990). Instead of using a linear function in (3.7), it is also possible to use a non-linear function such as a trapezoidal function in (3.8) or a sigmoid function in (3.10). Other common membership functions include normalized deprivation gaps below an upper bound with the lower bound being the minimum achievement value (Chakravarty 2006).43 A particularly interesting approach is Cheli and Lemmis (1995) Totally Fuzzy and Relative (TFR) method, in which the degree of membership is defined by the cumulative frequency distribution function. It is argued by the proponents of this approach that relative membership functions like this can be used uncontroversially with ordinal data because the distance between categories is defined directly from the relative frequency of the event. Recently, a series of membership functions based on the notion of inequality have also been proposed (Betti et al. 2006; Betti and Verma 1999, 2008; Cheli and Betti 1999). We do not provide a comprehensive list of membership functions but present four illustrations.44 Linear function (Cerioli and Zani 1990) 43 This function is similar to the FGT normalized deprivation gap. 44 We refer the reader to the following works for further study of alternative membership functions: Chiappero-Martinetti (2000), Deutsch and Silber (2005), Verkuilen (2005), Belhadj (2011), Betti et al. (2006), and Betti and Verma (2008). A key challenge of the fuzzy set approach is choosing and justifying the appropriate membership function, because measurement estimations are sensitive to the choice of membership function.[113] It would be necessary to run a series of robustness tests to check the sensitivity of various membership functions. A further challenge is that the choice of membership function and even the results are less intuitive than other approaches and therefore difficult to assess normatively or to communicate. Fuzzy aggregation across dimensions or across individuals presents additional challenges, and each requires similar robustness tests across membership functions. 3.5.3 AGGREGATION ACROSS DIMENSIONS Once the degree of deprivation in each dimension has been determined for each person, the next step involves aggregating across dimensions to obtain a synthetic individual measure indicating the degree to which someone is considered poor.[114] This step is equivalent to constructing the deprivation score in the counting approach described in Chapter 2. The aggregation function for dimensional deprivation membership values that has been most frequently used was suggested by Cerioli and Zani (1990) and Cheli and Lemmi (1995). It is the weighted arithmetic mean across the degree of membership in each dimension, where the weights represent the importance attributed to each dimension. Let Mi denote the aggregated degree of membership for individual i. Using the arithmetic where Wj denotes the weight attributed to dimension j. Note that, like the degrees of membership to each deprivation, the overall degree of membership Mi also ranges from 0 to 1, and it denotes the degree of membership to the set of the multidimensional^ poor people. Naturally, as stated by Chiappero-Martinetti (1996, 2000), the aggregation function in (3.12) can be generalized to the weighted generalized means family (see section 2.2.5). In terms of the dimensional weights, different alternatives have been proposed, including those by Cerioli and Zani (1990) and Cheli and Lemmi (1995). Chiappero-Martinetti (1996, 2000) summarizes other possible aggregation functions that use fuzzy logic operators based on Zadeh (1965), including the intersection approach, which are listed in Box 3.1. Further aggregation functions are presented in Betti and Verma (2004) and summarized in Betti et al. (2006). Most commonly, when the Mi function has been used in the fuzzy set literature, the implicit identification function has been ρ (Mi) = 1 if Mi > 0 and ρ (Mi) = 0 otherwise. In other words, a union criterion as been used implicitly to identify the multidimensionally poor. BOX 3.1 DIFFERENT IDENTIFICATION FUNCTIONS BASED ON FUZZY LOGIC OPERATORS 47 This box is a summary of the operators in Chiappero-Martinetti (1996) which are based on Zadeh (1965). BOX 3.1 (cont.) Weak intersection (algebraic product) 3.5.4 Aggregationacross people The final step consists of aggregating across individuals to obtain an overall indicator that quantifies the total extent of poverty.[115] Cerioli and Zani (1990) propose a fuzzy poverty measure that is the arithmetic average of the individual grade of membership to the set of the poor, given by Inserting (3.12) in (3.21), the poverty measure is given by As in other methods of multidimensional poverty measurement, the researcher or analyst implementing a fuzzy set approach needs to make a number of decisions in each of the measurement steps: selecting a membership function to identify deprivations, choosing a function and a weighting structure to aggregate deprivations, then selecting an aggregation function across individuals. 3.5.5 Acriticalevaluation The novel conceptual contribution of the fuzzy set approach lies at the identification stage of poverty measurement. The notable merit of the approach is that it tries to systematize into measurement the ambiguity frequently faced when defining the poor using crisp cutoffs. Using fuzzy set methods, analysts can construct empirical poverty indices that can reflect the joint distribution of deprivations when certain fuzzy logic operators are used. Some of the proposed measures within this approach can be meaningfully implemented with ordinal data, such as those based on relative membership functions. Others require value judgements that may be contested. Additionally, the measures are described normatively with reference to some of the basic properties of multidimensional poverty measurement discussed in Chapter 2. Specifically, certain measures have been shown to satisfy symmetry, replication invariance, scale invariance, weak monotonicity, population subgroup consistency, and dimensional breakdown. Using the arithmetic mean aggregation formula stated in (3.21) with membership functions that are not of the relative type, the measures also satisfy population subgroup decomposability. However, fuzzy set measures have some important challenges. Depending on the type of membership function used, fuzzy set measures may not satisfy other properties usually considered key: focus, weak transfer, and, in some cases, subgroup decomposability. For example, any measure based on an unbounded membership function, such as (3.7), (3.10), and (3.11), violates the focus axiom: poverty will change when the achievement of an arguably rich person—i.e. someone at the upper end of the distribution—changes. As Chakravarty (2006) shows, a measure using the membership function in (3.9) and an aggregation such as (3.21) satisfies a number of desirable properties, including focus, monotonicity, and transfer. Indeed, such a gap-based measure is actually a generalized FGT measure, which coincides with the non-fuzzy approach to poverty measurement traditionally used not only in FGT measures but in other poverty measures as well (Sen 1976, for example). The only difference is a matter of interpretation of the gap as a degree of membership to the set of the deprived. In contrast, in the standard version of Cerioli and Zani (1990) and Cheli and Lemmi (1995), which use relative membership functions such as the one in (3.11), the measures are not decomposable across population subgroups because they depend on the rank order across categories and are relative to the frequency distributions. In terms of measures based on membership functions that use a lower and an upper bound, there are two fundamental concerns. First, reductions in achievements among those who are certainly poor are not reflected in the overall measure unless the achievement value falls lower than the lower bound, i.e. in this range they only satisfy weak monotonicity. Second, a measure using such a membership function will definitely violate the transfer axiom. If there is a progressive transfer between a person whose achievement is above the lower bound zj but below the upper bound zj and a person whose achievement is below the lower bound zj so that the latter does not surpass it, the measure will reflect an increase in poverty rather than registering the expected decrease. Conversely, a regressive transfer between the same two persons will create a decrease in the overall poverty measure rather than the expected increase. A second challenge with the fuzzy set approach is the grounds on which membership functions are selected and justified, and how robust results are to the selection of a particular membership function. In this case, one needs to justify the choices, and perform sensitivity analyses or robustness tests on the alternative membership functions used at different steps of poverty measurement. This raises the question as to how value is added by performing essential robustness tests across membership and aggregation functions, rather than performing these directly on a set of crisp deprivation and poverty cutoffs. One might argue that in a crisp set, the method is easier to communicate and so are the underlying normative choices. A third challenge relates to the use of ordinal data. Some fuzzy set approaches in effect cardinalize ordinal data through assumptions such as equidistance between points. In this book, we adopt a rather more cautious approach to ordinal data as a starting point. Assumptions regarding the value of ordinal data must themselves be subject to a further series of evaluations as to whether the same policy-relevant results hold for alternative plausible cardinalizations of the same ordinal data. In sum, the fuzzy set approach has contributed greatly to the literature by bringing attention to the importance of the identification of the poor, which is very often—paradoxically—overlooked in poverty measurement methodologies. However, in the current state of the literature, measures that propose incorporating fuzziness at the identification step violate some basic properties of poverty measurement such as focus and transfer, and may require quite an array of sensitivity and robustness analyses. There is thus room for further developments in a fuzzy set measure that can incorporate the ambiguity in identification while respecting key properties. At the moment, non-fuzzy approaches to measurement typically deal with ambiguity in the identification of the poor by testing a measure's robustness to changes in the cutoffs used, as is recommended when using the AF methodology and addressed in detail in Chapter 5. The following section discusses in more detail the measures based on axiomatic approaches. 3.6