Macromolecules and cellular physiology
Although we have considered some aspects of lipid structure, especially related to membrane structure, it is apparent that normal cellular function depends on a myriad of biochemical reactions and macromolecules.
At first glance, the number of biologically relevant molecules in cells seems overwhelming. However, some relatively simple combinations of atoms—methyl (-CH3), hydroxyl (-OH), carboxyl (-COOH), and amino (-NH3) groups—appear repeatedly in biologically important molecules. Second, repeating combinations of relatively simple compounds create most of the large complex macromolecules. Most of the organic molecules in cells are derived from four major groupings of molecules. These are simple sugars or carbohydrates, amino acids, fatty acids, and nucleotides.Major phases of metabolism can be subdivided in a variety of ways, but a simplistic view would consider activities that build new cellular components (anabolism) compared with those that break down various cellular elements (catabolism). Interestingly, both processes are occurring simultaneously. For example, catabolism of various nutrient compounds by digestive tract tissues provides the structural building blocks for other tissues to grow or synthesize and secrete products (anabolism). Other nutrients are Catabolized to provide elements needed for energy production (usually ATP). We begin our study of cellular physiology by first considering major classes of macromolecules. However, our discussion is no substitute for related classes in chemistry and biochemistry. Our goal is to provide an overview to aid your understanding of physiological processes.
Proteins
In the absence of disease or trauma, most cellular proteins are synthesized from free amino acids or peptides absorbed from the bloodstream. The cell membrane (and associated carrier proteins) regulates the uptake of these molecules from the interstitial fluids.
Understanding of amino acid transporters is an area of active research, but many features are common between tissues. Some of these transporters show an ion dependence (e.g., Na+, CF, and K+) or use an H+- gradient to drive transport. The Na+-dependent system A transporters for neutral amino acids are believed to regulate the accumulation of neutral amino acids within the cells when compared with plasma concentrations. There is much interest in regulation of amino acid uptake to better understand factors limiting milk and meat protein synthesis. From an animal production viewpoint, much of the value of animal products resides in their protein content, for example, meat, milk, and eggs.While the significance of proteins as important building blocks in anabolism is easily appreciated, the enzymes that are vital for cell function are also proteins. Like most biologically critical macromolecules, linking together subunit monomers—the amino acids—in this case allows a large variety of proteins to be generated. Individual amino acids share the common structure illustrated in Figure 2.18. The R (or residual group) is attached to the α-carbon and is unique for each amino acid. For the simplest, the amino acid glycine, the R is a hydrogen atom. Individual amino acids are bound together by a dehydration synthesis reaction (so named because water is
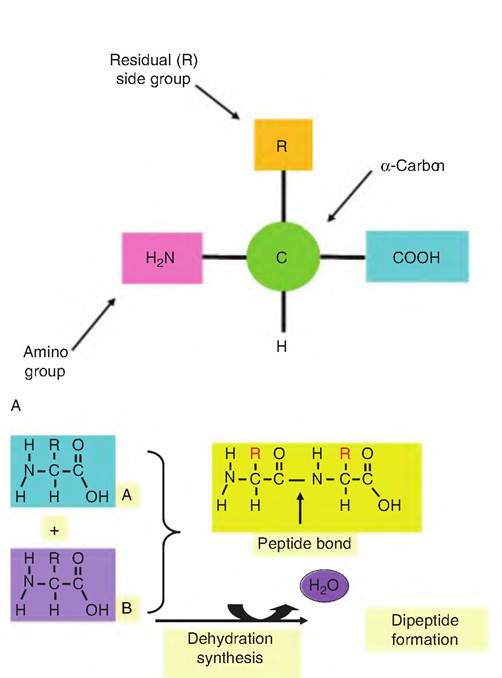
B
Fig. 2.18. Structure of amino acids. Panel A shows the general structure of an amino acid. Formation of a dipeptide is illustrated in panel B. Two amino acids (A and B) are linked by the formation of a peptide bond between the carboxylic acid moiety of one amino acid and the amine group of the other amino acid. In this process a molecule of water is produced. The reverse reaction, hydrolysis, requires the addition of water to cleave the peptide bond.
liberated in the process).
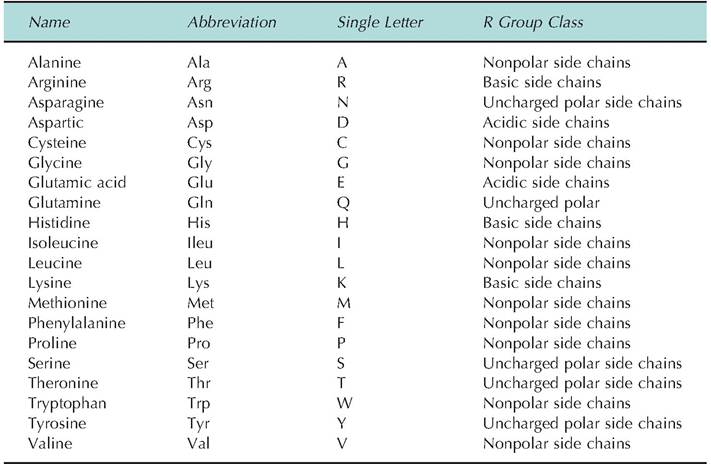
Newly created covalent bonds between amino acids are called peptide bonds (Fig∙ 2.18).There are 20 common amino acids. Some are considered essential amino acids because they must be supplied in the diet. Others can be created by intermediary metabolism. However, specific amino acids considered essential vary between species, especially in ruminants compared with nonruminant species. This is because the bacteria and protozoa of the ruminant can generate amino acids not initially available in the diet fed to the animals. As illustrated in Figure 2.18, all amino acids have two functional (or reactive) groups: an amine (-NH2) and a carboxylic acid residue (-CHOOH). Differences in the number and arrangement of atoms in the R group give each of the amino acids its unique chemical attributes. For example, if the side group is a simple string of hydrocarbons (leucine, for example), this region of the amino acid will be very hydrophobic, much like fatty acid tails of a phospholipid. Other side groups, for example, the inclusion of an additional amine group (lysine, for example), would make the amino acid very hydrophilic and more basic. The various amino acids can be categorized based on the properties that the R groups give to the molecule. These are acidic,basic, uncharged polar, or nonpolar attributes. In addition to the common names, the amino acids are also denoted by simple abbreviations or a single letter code. Other important amino acids or their derivatives, for example, ornithine, 5-hydroxytrytophan, L-dopa, and thyroxine, are found in the body, but these molecules do not typically occur in proteins. Interconversions between some of the amino acids, as well as between amino acids and intermediates of carbohydrate metabolism associated with Krebs cycle reactions also occur as part of normal cellular activity. Transamination reactions allow the conversion of selected amino acids into their corresponding keto acid and the simultaneous conversion of another keto acid into an amino acid.
Oxidative deamination of amino acids occurs primarily in the liver. This initially leads to the generation of ammonia, which is highly toxic to cells. Fortunately, most ammonia is rapidly converted into urea, which can then be excreted. Some of the properties of the amino acids are given in Table 2.6. These properties explain much of the physicochemical properties of proteins.Proteins are long chains of amino acids linked by peptide bonds. Two amino acids create a dipeptide, three a tripeptide, and so forth. By definition, 10 or more linked amino acids are called polypeptides, and those with greater than about 50 amino acids are simply called proteins. Since each of the amino acids have unique properties because of variation in the R groups, the sequence of amino acids produces polypeptide and protein chains with correspondingly varied and complex properties. With the availability of 20 different amino acids, the variation of possible structures and therefore functional properties is very large. This is analogous to the huge number of words that can be created with the 26 letters of the alphabet.
Structurally, proteins are described at four levels of organization. The linear sequence of amino acids in a protein is called the primary structure of the protein. This can be thought of like beads on a string. However,
Table 2.6. Characteristics of common amino acids.
proteins in solution do not simply exist as a long strand. Instead, variations in the properties of the R groups allow interactions between the protein and other molecules in the local environment as well as interactions between other amino acids of the same protein chain. This twisting and bending produces a more complex secondary structure. One of the more common results is the formation of coils that can be imagined like a coiled telephone cord. Portions of a protein organized in this way are called a helix segments or regions.
The a helix configuration is stabilized by hydrogen bonds that occur between NH and CO groups of amino acids of the primary chain that are spaced about 4 amino acids apart along the series. To reinforce the significance of the primary sequence, this interaction can only occur if the particular side groups of the amino acids allow hydrogen bonds to form. The a helix formation only occurs within a single protein chain. In contrast, the formation of β-pleated secondary structure can occur via interactions with amino acids within the same protein or by interactions between independent proteins. In this secondary structure arrangement, the amino acids are oriented side by side to produce a layer somewhat like a pleated ribbon. A given protein can exhibit both a helix and β-pleated sheet structure in different regions of the protein. A further or tertiary structure occurs when «-helical or β-pleated regions of a protein twist or fold upon one another to create globular-like structure. To maintain this complex array, both hydrogen bonds and covalent bonds are required. When two or more independent protein chains interact to produce larger aggregates, the proteins are said to have quaternary structure. Examples include the four chains that create functional hemoglobin or the 12 proteins that create the enzyme fatty acid synthetase.As the discussion suggests, the three-dimensional structure of a protein is critically important in allowing the protein to carry out its function. Since much of the secondary, tertiary, or quaternary structure depends on interactions between amino acids and the creation of hydrogen and/or ionic bonds, it is easy to see that changes in the local environment of the protein can markedly impact function. For example, changes in pH or aqueous conditions can markedly alter interactions that depend on ionic or hydrogen bonds. These changes in protein structure are called denaturation. Depending on the degree of insult and the particular protein involved, when conditions return to normal, the protein can return to its appropriate, functional state.
As an example of irreversible denaturation, consider what happens to the jelly-like albumin of the egg when it is heated or it mixed with a bit of vinegar to make a sauce.Proteins can also be divided into fibrous or globular classifications. Fibrous proteins are usually elongated and are relatively insoluble. Examples include structural proteins found in the connective tissues of blood vessels, in subcutaneous regions, surrounding muscles or other glandular structures, and in tendons and ligaments. The most abundant of these is collagen, which is made by fibroblasts located throughout the body. Collagen begins with the synthesis of a monomeric form, helical tropocollagen. These precursor molecules are modified and packaged side by side to yield strong, rope-like structures. Other types of collagen occur in the basement membrane just underneath epithelial cells. In fact, collagens are the most abundant proteins in the body. Other examples of fibrous proteins include other connective tissue proteins, elastic, keratin, and the contractile proteins of muscle cells, actin and myosin.
Globular proteins, by contrast, are generally very soluble, compact, and spherical. These proteins are reactive and are therefore more fragile than the fibrous proteins. Since their functionality depends on their three-dimensional shapes and high degree of structural organization, disruption or denaturation effectively destroys function. Enzymes, antibodies, and protein hormones are examples of globular proteins. Adequate functioning of globular proteins depends on the maintenance of active site(s) of the protein. The consequence of denaturation of such a globular protein is illustrated in Figure 2.19.
Classic autoradiographic studies, which traced the movement of radiolabeled amino acids through the secretory cells, established that the site of protein synthesis was the RER. For example, after rats were injected with [3H]-leucine or tissue explants were incubated with radiolabeled leucine, the percentage of label in the RER subsequently fell with a following peak in labeling of the Golgi region of the secretory cells. Within 30 minutes of exposure, label began to decrease in the Golgi but increase in the alveolar lumen. These simple but convincing studies demonstrated that after synthesis in the RER, proteins are rapidly transported to the Golgi for packaging into secretory vesicles and subsequent exocytosis.
Steps for protein synthesis are essentially the same for all cells, although final packaging and fate of new synthesized proteins varies between cells and tissue types. Aside from directing its own replication, DNA also directs protein synthesis by its capacity to generate mRNA. Each gene is composed of a segment of DNA, which carries the chemical instructions for synthesis of one polypeptide chain in its arrangement of nucleotide bases (adenine, thymine, cytosine, and guanine). Each sequence of three bases—the triplet code—directs the joining of a specific amino acid in the mature mRNA molecule. Although one-half of the double-stranded DNAserves as template for synthesis of the mRNA (transcription), not all of the nucleotides
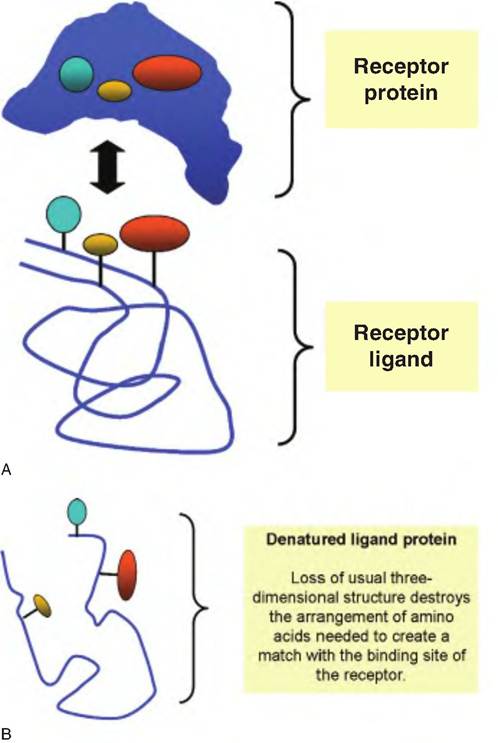
Fig. 2.19. Protein structure and function. Protein interactions and significance of secondary and tertiary structure is illustrated. Functional binding between a hormone receptor and the binding hormone or ligand requires that the ligand achieve the correct shape and orientation so that the amino acids that make the binding site match the active site of the receptor. This is illustrated by the correspondence between the two proteins (panel A). When the ligand protein becomes denatured, these critical amino acids lose their alignment so that the hormone can no longer bind to the receptor and function is lost (panel B). Similar protein interactions are required in biochemical reactions, for example, substrates binding to active sites of enzymes, neurotransmitters binding to their receptors, antibodies binding to antigens, or molecules binding to protein transporters in the cell membrane.
in the gene appear in the final mRNA blueprint. The genes of higher organisms contain exons, the aminoacid specifying sequences, separated by introns. These noncoding introns range from 60,000 to 100,000 nucleotides in length. Transcription of a particular gene depends on the binding of a transcription factor to a site on the DNA adjacent to the start sequence for the gene. This region is the promoter. The transcription factor mediates the binding of the enzyme RNA polymerase. This enzyme acts to open the DNA helix, and the DNA segment coding for the protein is uncoiled. Only one strand of the DNA, the sense strand, serves as the template for the creation of a complementary mRNA. However, before the mRNA can direct protein synthesis, the noncoding introns are enzymatically removed before the newly made mRNA exits the nucleus for translation. Single-stranded RNA also differs from double-stranded DNA in having the sugar ribose instead of deoxyribose and the base uracil instead of thymine. This feature provides a ready means to access the ability of cells for proliferation or synthesizing of proteins by measuring the incorporation of radiolabeled thymidine or uracil, respectively.
While it is beyond the scope of this book, elegant molecular studies have confirmed that the specific proteins for secretion are synthesized by membrane- associated ribosomes and that the newly made proteins have short sequences of amino acids that serve as signals to allow binding and vectoring of the nascent protein into the cisternal spaces of the RER. The signal peptide is ultimately cleaved as the protein progresses to the Golgi apparatus for possible posttrans- Iational modification, that is, enzymatic addition of sugar residues or phosphate groups. The proteins are ultimately released from the Golgi as secretory vesicles. From here they migrate to the apical membrane of the cell where they are released by exocytosis (see Fig. 2.4). Thus, mechanisms of protein synthesis are essentially the same in all cell types. However, total protein synthesis and the degree to which proteins are manufactured for secretion vary markedly from cell type to cell type.
Carbohydrates
As with proteins, carbohydrates are utilized as both structural components in cells and as precursor molecules for energy production. The primary dietary carbohydrates are polysaccharides, disaccharides, and monosaccharides. Carbohydrates are classified according to size and relative solubility. For example, monosaccharides are more soluble than the larger polysaccharides. In both plants and animals, polymeric forms of carbohydrates are stored as relatively insoluble granules, that is, starch in plants and glycogen in animal cells. Common monosaccharides include those with 3, 4, 5, 6, or 7 carbons; these are trioses, tetroses, pentoses, hexoses, and heptoses, respectively. Derivatives of trioses are generated when the enzymes of the glycolysis biochemical pathway break down the common hexose sugar glucose. These molecules are used by the cells for various catabolic and anabolic activities. For example, trioses are used to produce glycerol needed to create the backbone for the attachment of fatty acids in triglycerides (see Fig. 2.2). Understanding this biochemical pathway is critical to
gaining an appreciation of cellular energy production. Pentose sugars (ribose and deoxyribose) are key components of nucleotides, nucleic acids, and several coenzymes. The hexose monosaccharide, glucose, plays an especially critical role in intermediary metabolism, particularly as an energy source. For the hexose sugars, glucose, galactose, and fructose are especially important. These monosaccharides serve as the monomers ofbuilding blocks for generation of more complex carbohydrates needed by the cells. Many glycoproteins (proteins with attached sugar residues) appear on cell surfaces. Other complex polysaccharides are secreted into the connective tissues, for example, the glycosaminoglycans, where they serve important roles in maintenance of tissue structure and hydration.
Carbohydrates contain carbon, hydrogen, and oxygen, with the hydrogen and oxygen occurring in a 2:1 ratio as in water. This explains the word carbohydrate, that is, hydrated carbon. Structurally, these simple sugars can be represented as chains, but more often, a cyclic ring structure is preferred. Figure 2.20 illustrates the formulae and structures of some of these common simple sugars. Compounds that have the same structural formulae but have different spatial arrangement of their atoms are called stereoisomers. The presence of carbon atoms attached to four different atoms or groups, known as an asymmetric carbon, allows for the formation of isomers. The number of possibilities depends on the total number of asymmetric carbons in the molecule (n) and is determined by the expression 2n. Glucose with its 4 asymmetric carbons has 16 possible spatial isomers. Furthermore, the orientation of the H and OH groups around the carbon adjacent to the terminal primary alcohol residue (OH group) determines whether the sugar is a D- or L-isomer. Nearly all monosaccharides in mammals are D-isomers.
Whether they are created via dehydration synthesis or as a consequence of digestion from larger polysaccharides, disaccharides are physiologically important. One of the most common is lactose or milk sugar. It is produced by linking glucose and galactose. For most mammals, lactose supplies much of the energy needed by the suckling neonate as well as the monomeric building blocks needed for rapid tissue development. Maltose, which derives from two glucose molecules, is a common cleavage product generated by the hydrolysis of starch. Table sugar, sucrose, is a combination of glucose and fructose. As the name suggests, 6-carbon fructose is a common fruit sugar. It also is a component in reproductive tract secretions. Figure 2.21 illustrates the structures of some of these common disaccharides.
Whether a plant starch or glycogen, both are polymers of glucose and are the essential sources of the glucose that is used throughout the body in monogastric species. Although glucose is also essential for
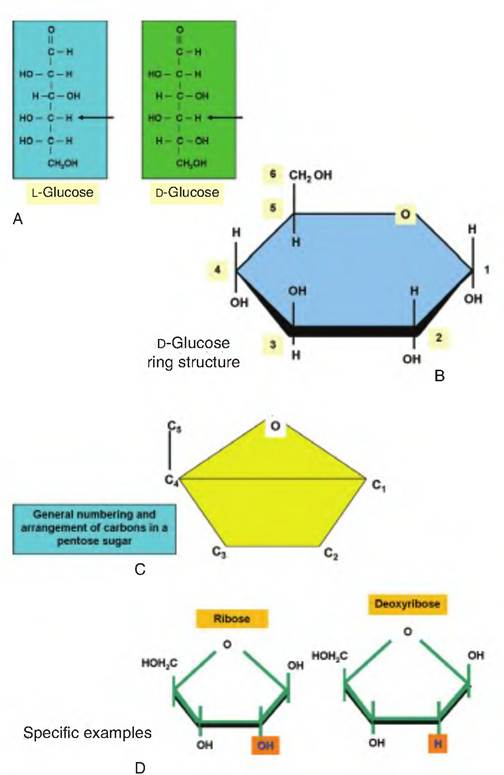
Fig. 2.20. Structure of sugars. Panel A provides line structures for two structural isomers of the common hexose monosaccharide, glucose (arrows). Panel B gives the cyclic structure for α-D-glucose. The arrangement and numbering of carbons in a pentose sugar appears in panel C. Panel D shows the difference between ribose and deoxyribose, the sugar residues present in RNA and DNA, respectively.
ruminants, fed starches are fermented by rumen microorganisms so that little, if any, glucose is available for absorption across the small intestine. For these animals, the primary fermentation products—acetate, butyrate, and propionate—supply the precursors for fatty acid synthesis and energy production. In particular, portal blood supplied to the liver from the small intestine allows for the conversion of most of the absorbed propionate to glucose for use by the cells. This is called gluconeogenesis. It is important in all animals at times but is especially critical in ruminants since glucose from the diet for absorption across the small intestine is nearly nonexistent.
Dietary starches are first attacked for hydrolysis by α-amylase in the saliva. This initial breakdown is suppressed by the reduced pH of the stomach; that is,
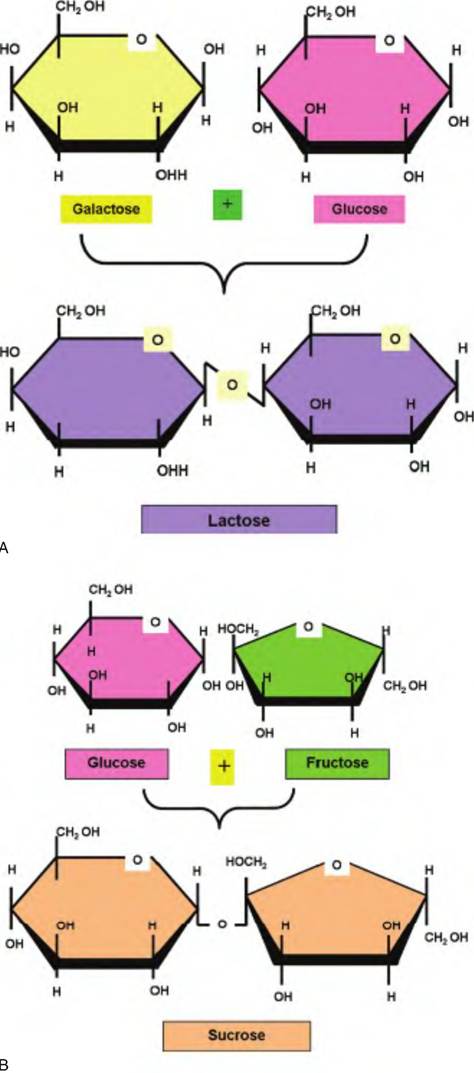
Fig. 2.21. Structure of disaccharides. Panel A shows the combining of galactose and glucose to produce the disaccharide lactose or milk sugar. Panel B depicts the creation of the disaccharide sucrose from the combination of glucose and fructose. Maltose, a disaccharide composed of two molecules of glucose, follows a similar pattern.
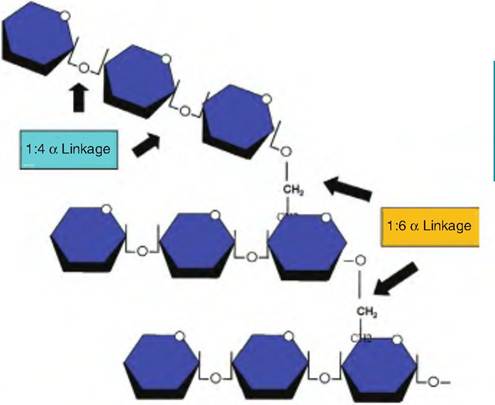
Fig. 2.22. Structure of glycogen. A simple example of the structure of a portion of glycogen is illustrated. Repeating glucose monomers are linked together to form large branched chain polymers. These relatively insoluble molecules serve as ideal storage products and appear in liver and muscle cells as dense granules. Cleavage of the 1:4a linkages that produce the linear chains and the 1:6a linkages that make branches depend on two different enzymes when glycogen is hydrolyzed for use by the cell.
α-amylase pH optima is near neutrality. However, hydrolysis of starches increases again as starch reaches the small intestine and additional amylases from the pancreas and small intestine appear. Glucose is stored primarily in liver and muscle cells in the form of glycogen. This reserve of glycogen can then be mobilized to supply glucose when needed. When ATP is plentiful and stocks of glycogen are sufficient, additional energy reserves produced by the conversion of glucose to acetate and ultimately fatty acids are stored as triglycerides in adipocytes. Figure 2.22 illustrates the structure of glycogen. Subsequent chapters will describe the biochemical reactions and pathways involved in catabolism of glycogen and other carbohydrates to supply the energy needs and building blocks for synthesis of important macromolecules.
Lipids
Although we have discussed triglycerides and phospholipids related to membrane formation, other lipids are also important. Some are messenger molecules. Details of the endocrine system and other aspects of cell signaling will be considered in subsequent chapters, but some appreciation of these special lipids is warranted. Steroids are structurally very different from triglycerides. They are derived from the parent molecule cholesterol. Despite its "bad press," cholesterol is nonetheless essential. In addition to serving as
the parent molecule for steroid hormone production, it is also a vital element in membranes, where it acts to increase membrane fluidity. It is also essential for the production of vitamin D and production of bile salts.
Unlike the hydrocarbon chain of the fatty acids, cholesterol is composed of a series of interlocking rings with a side chain. Specifically, the four interlocking A, B, C, and D rings of the cholesterol core contain the Cyclopentanohydrophenanthrene nucleus that occurs repeatedly in all of the steroid hormones. For example, two structural types of steroid hormones are made in the cortex of the adrenal gland: those that have a 2-carbon side chain attached at position 17 of the D ring for a total of 21 carbons, the C21 steroids, and those that have a keto or hydroxyl group at position 17 for a total of 19 carbons, the C19 steroids. Most C19 steroids have a keto group at position 17 and are often simply called 17-ketosteroids. The C19 steroid hormones have androgenic or testosterone-like effects or actions. The C21 steroids of the adrenal gland are either mineralocorticoids or glucocorticoids. The mineralocorticoids have primary effects on sodium and potassium excretion. The major hormone in this class is aldosterone. The glucocorticoids, as you might guess from the name, have primary effects related to glucose and carbohydrate metabolism. Examples of specific steroids in this class are cortisol and corticosterone. Other sex steroids, for example, estrogen and progesterone, will be discussed in subsequent chapters. A major point of our discussion at this point is to appreciate the fact that despite the seemingly small differences in structure between, for example, estrogen and testosterone, these two steroid hormones have markedly different effects. This is directly related to the specificity of hormone receptors that are expressed in various target cells. That is, estrogen molecules bind very poorly to androgen receptors, and, conversely, testosterone binds very poorly to the estrogen receptor.
The eicosanoids are a diverse family of lipids generated from a 20-carbon fatty acid called arachidonic acid. Arachidonic acid is plentiful in the plasma membrane of the cell. The four major groups of eicosanoids include prostaglandins, prostacyclins, thromboxanes, and leukotrienes. A commercial preparation of prostaglandin F2α, Iutalyse (dinoprost tromethamine), is familiar to many dairy and beef producers because it is used in a management scheme to synchronize estrus in cattle. The product acts to cause early dissolution of the corpus Iuteum on the ovary. Various eicosanoids are important in the control of blood pressure, GI tract motility, vasoconstriction, and blood flow.
Since the major lipids in plasma do not circulate freely in the aqueous environment of the blood, fatty acids and other important lipids are transported bound to carrier molecules. Free fatty acids are bound to albumin (a major protein produced by the liver). Most of the cholesterol, triglycerides, and phospholipids appear in a complex with lipoproteins for transport. There are five families of lipoproteins that vary with respect to the ratio of protein to lipid in the complex. They can be distinguished based on the position they migrate to following high-speed centrifugation. Those with greater lipid contents (less density) orient closer to the top of the centrifuge tube, and those with less lipid orient further toward the bottom of the tube. This is somewhat like the cream rising to the top of a container of nonhomogenized milk. This explains the description of the lipoproteins as very low- (VLDL), intermediate- (IDL), low- (LDL), or high- (HDL) density lipoproteins. The other class includes the chylomicra that are produced in the intestinal villi and are critical in initial packaging and transport of digested triglycerides. Lipoproteins are topics in the popular press because of their involvement with lipid and cholesterol transport in the blood and relationships with health. For this purpose, usually only the major classes, HDLs and LDLs, are distinguished. The amounts and ratios of these in the blood are important diagnostic tools related to cardiovascular health in humans and animals. Cells can take up cholesterol and other lipids from the blood. Most of the cholesterol is associated with LDLs. When cells need cholesterol to make new membranes or other purposes, they synthesize transmembrane receptors for the LDL proteins. These receptor proteins migrate within the membrane until they become localized in clathrin-coated pits. These are areas of the cell membrane that are destined for endocytosis. LDLs that bind to the receptors are subsequently taken into the cells as part of an internalized vesicle. These coated vesicles are processed by interactions with lysosomes to release the cholesterol for use by the cell. Interestingly, more than 25 different receptors are processed via this clathrin-coated pit pathway. In the case of cholesterol, if the LDL receptor-mediated uptake of cholesterol is blocked, this leads to excess accumulation of cholesterol-laden LDL in the blood, and this excess cholesterol is believed to contribute to production of atherosclerotic plaques and consequently cardiovascular disease. The study of families with strong genetic links to cardiovascular disease initially led to discovery of this relationship. One of the mechanisms responsible for increased disease was a mutation that prevented normal expression of the LDL receptor. Structures of some of selected lipids are illustrated in Figure 2.23.
Nucleic acids
Understanding DNA or RNA requires an appreciation of the molecules that compose these macromolecules.
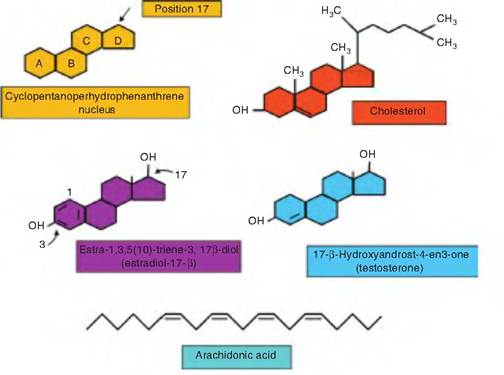
Fig. 2.23. Structure of specialized lipids. Structures of some of the specialized lipid molecules are illustrated. Cholesterol and the steroid hormones and their relatives have the Cyclopentanohydrophenanthrene nucleus with four hydrocarbon rings in common (upper panel). Additions of side chains to the 1 7 carbon, methyl, or hydroxyl groups, or addition of double bonds in the A ring lead to production of cholesterol, estradiol, testosterone, and other steroids. The relatively linear hydrocarbon chain of the 20-carbon arachidonic acid becomes folded and modified to yield various prostaglandins, thromboxanes, or leukotrienes.
These nucleic acids are produced from combinations of nucleotides, but nucleotides are in turn a combination of three elements: (1) a phosphate group, (2) a pentose sugar (either ribose or deoxyribose), and (3) a nitrogen-containing base (either a purine or a pyrimidine). There are three types of pyrimidines: cytosine (C), thymine (T), and uracil (U). The two types of purine are adenine (A) and guanine (G). Thymine is unique to DNA, and uracil is unique to RNA.
Variation between DNA strands, or in other words between different genes, depends on the particular sequence of nitrogenous bases that occur. A combination of either deoxyribose or ribose and one of the bases is called a nucleoside. Include the phosphate group (sugar + base + phosphate) and you have a nucleotide. The phosphate groups are joined to the hydroxyl group on the C5 carbon of the sugar residue. Moreover, as you will see related to ATP production, it is not uncommon to find mono-, di- or triphosphates attached to many nucleotides. To illustrate, a combination of the purine adenine + deoxyribose + one phosphate makes adenosine monophosphate or AMP. The same base and sugar with two phosphates makes ADP or adenosine diphosphate. If a third phosphate is added, adenosine triphosphate or ATP is generated.
Single strands of DNA or strands of RNA are produced when a phosphate group from one nucleotide (attached to the C5 carbon of the pentose sugar) links with the hydroxyl group located on the C3 carbon of the pentose sugar of another nucleotide. Thus, the nucleic acid chain grows in a 3' to 5' direction. This means that along the course of a growing nucleotide chain, the nitrogenous bases are not directly linked with other bases in the same chain. For DNA, this arrangement allows for complementary base pairing occurring between adjacent chains. This is the essence of creation of double-stranded DNA. The DNA molecule is most easily imagined like a ladder. The outside supports of the ladder are represented by the covalently linked pentose sugars and phosphate groups of the nucleotides. Complementary bonding between bases creates the rungs of the ladder. Now if the ladder is imagined as being twisted like a spiral staircase, this gives a reasonable approximation of the DNA.
However, it is important to remember that while linkages between sugars within a chain are maintained by strong covalent bonds, the interactions between nitrogenous bases between two DNA chains depends on simple hydrogen bonding, similar to the interactions between adjacent water molecules (see Fig. 2.1). These hydrogen bonds, while not strong individually, are critical because of their abundance; this also allows the double-stranded DNA to readily unzip as required for gene transcription. Once this is accomplished, the strands can then readily rejoin. Interactions between bases allows for bonding between adenine and thymine, cytosine and guanine. These linkages, A + T and C + G, are called complementary bonds or complementary bases. However, the stands are oriented so that one is oriented in a 5' to 3' direction and the other 3' to 5' (the numbering is based on the orientation of phosphate groups linking the 3 or 5 carbons of the pentose sugar). In single-stranded RNA molecules, the bases are A, G, C, and U (replaces the T found in DNA). The pentose sugar is ribose instead of deoxyribose. Examples of nucleic acid structures and components are illustrated in Figure 2.24 and Figure 2.25.