THE OPERATION MODEL AND FUNCTIONAL TYPOLOGY
Algorithmic selection is applied for a number of purposes. It is the technological basis or functional feature of many of the most popular and economically successful Internet services, among others, by Google, Facebook, Amazon, Netflix or Spotify.
Applications and groups of services based on algorithmic selection often contain prefixes such as ‘algorithmic’ or simply ‘algo’ (e.g., algo trading), ‘computerized’ or ‘computational’ (e.g., computational advertising), ‘smart’ or ‘intelligent’ (e.g., intelligent filtering). This plurality of applications, services and terms constitutes a challenge for research. In order to explore algorithmic selection it has to be defined and distinguished from other phenomena. Moreover, it is helpful to differentiate certain groups of applications in order to compare and contrast functions, markets and risks associated with certain types of application.Although there are numerous definitions of algorithm, it can generally be described as a finite series of precisely described rules or processes to solve a problem. It is a sequence of stages that transforms input through specified computational procedures (throughput) into output (Cormen et al., 2009; Mossenbock, 2014). Generally, all algorithmic selection applications can be described with the help of a basic input-throughput-output model (ITO), depicted in Figure 19.1.
The centerpiece of this process model is the throughput stage at which the algorithms operate that define the input-output relationship. Starting from a user request and available user characteristics they apply statistical operations to select elements from a basic data set (DS1) and assign relevance to them. Accordingly, algorithmic selection on the Internet is defined as a process that assigns relevance to information elements of a data set by an automated, statistical assessment of decentrally generated data signals.
Input, throughput and output vary for different applications and services. In many cases, big data serves as input, but there is a wide spectrum of input sources, depending on the field ofJohannes M. Bauer and Michael Latzer - 9780857939845
Downloaded from EIgarOnIine at 04/05/2017 01:09:57AM via Hong kong University of Science and Technology
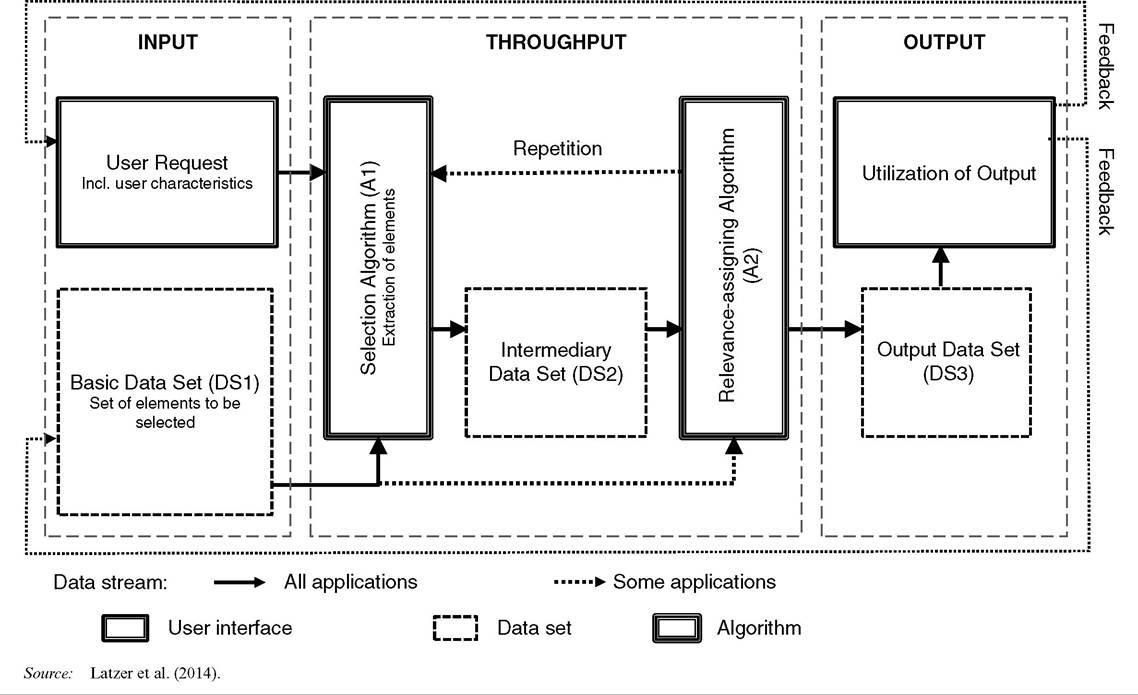
Figure 19.1 Input-throughput-output model o f algorithmic selection on the Internet
Table 19.1 Functional typology of applications using algorithmic selection
| Types | Examples |
| Search | General search engines (e.g., Google search, Bing, Baidu) Special search engines (e.g., Mocavo, Shutterstock, Social Mention) Meta search engines (e.g., Dogpile, Info.com) Semantic search engines (e.g., Yummly) Questions & answers services (e.g., Ask.com) |
| Aggregation | News aggregators (e.g., Google News, nachrichten.de) |
| Observation/ surveillance | Surveillance (e.g., Raytheon’s RIOT) Employee monitoring (e.g., Spector, Sonar, Spytec) General monitoring software (e.g., Webwatcher) |
| Prognosis/forecast | Predictive policing (e.g., PredPol), Predicting developments: success, diffusion etc. (e.g., Google Flu Trends, ScoreAHit) |
| Filtering | Spam filter (e.g., Norton) Child protection filter (e.g., Net Nanny) |
| Recommendation | Recommender systems (e.g., Spotify, Netflix) |
| Scoring | Reputation systems: music, film, etc. (e.g., eBay’s reputation system) News scoring (e.g., reddit, Digg) Credit scoring (e.g., Kreditech) Social scoring (e.g., Klout) |
| Content production | Algorithmic journalism (e.g., Quill, Quakebot) |
| Allocation | Computational advertising (e.g., Google AdSense, Yahoo! Bing Network) Algorithmic trading (e.g., Quantopian) |
Source: Latzer et al.
(2014).
application. The throughput process is characterized by the assignment of relevance (A2) and respective selections (A1), and there is a multitude of different codes based on different operating modes (e.g., matching, sorting or filtering algorithms). Finally, the output (DS3) also takes on different forms (e.g., rankings, recommendations, biddings, text, and music). In many cases, it serves as an input to subsequent algorithmic selection processes.
Applications can be differentiated according to their central function, that is, the general purpose that these applications serve. Here, a functional typology is proposed that covers nine categories (Table 19.1). It should be kept in mind, though, that these categories are neither meant to be all embracing nor mutually exclusive.
Search applications have become indispensable tools for exploring the Internet and are the most widespread algorithmic services with great economic significance. Relevance is assigned to elements according to the best fit with users’ queries. Alongside general purpose algorithmic search engines such as Google and Bing, there are a vast number of applications for special (vertical) searching in particular domains or regarding particular issues (e.g., Mocavo, a genealogy search engine). General search engines play an important role in the growing e-commerce sector, which has led to the development of connected industries of web content production and website optimization (known as search engine optimization, SEO, agencies) as well as search engine marketing (SEM) specialists. The gatekeeping role of general search engines and especially the dominant market position of Google (Haucap and Stuhmeier, Chapter 9 this volume) are highly contested issues in the public debate.
Aggregation applications, most prominently news aggregators such as Google News, collect, categorize and regroup information from multiple sources into one single point of access (Zhu et al., 2001; Aguila-Obra et al., 2007; Calin et al., 2013).
Unlike syndicators, aggregators often acquire the data they offer (e.g., news) without paying. This business model has attracted severe criticism and debate, especially regarding the impact on the profitability of other media industries (in particular, newspapers) and alleged intellectual property rights violations (Isbell, 2010; Weaver, 2013).ObservationZsurveillance applications such as Raytheon’s Rapid Information Overlay Technology (RIOT) have gained prominence lately and were heavily criticized in the context of the National Security Agency scandal (Greenwald and MacAskill, 2013). Not only do secret service agencies make use of algorithmic surveillance, but companies also employ surveillance technologies, for example for social sorting (Lyon, 2003), to control their networks, employees (Ciocchetti, 2011) and customers (Pridmore and Zwick, 2011). Many applications monitor online behavior in order to detect abnormalities associated with certain risks (e.g., credit card fraud, cyber attacks). Moreover, for several other algorithmic applications, such as forecasting services or computational advertising, observation and surveillance are a basic function.
PrognosisZforecast applications aim at predicting future behavior or scenarios (Kusters et al., 2006; Issenberg, 2012; Silver, 2012), for instance, in areas such as consumption, natural disasters, entertainment hits and crime. Respective applications, such as the predictive policing technology PredPol, are of particular importance in the context of big data analyses. The distinction between surveillance applications and forecast applications is often not clear-cut, as both employ similar dataZreality mining methods, or are applied in combination. To distinguish them, surveillance applications are sometimes called ‘now-casting’ applications (Banbura et al., 2010; Faigle, 2010), which points to time as the differentiating factor. Surveillance refers to the present (real time), while forecasting relates to future occurrences.
Filtering applications such as the Norton spam filter often work behind the scenes as passive or active information filters (Hanani et al., 2001). Passive filters select certain elements, but instead of displaying these to the user, they prevent access to them. Algorithmic or intelligent filtering is applied, for instance, to counter spam or malware. However, filtering is also used to block political information, especially in authoritarian regimes (Deibert et al., 2008, 2010).
Recommendation applications such as music recommendations by Spotify are among the most widely known services. These online applications are intended to replace traditional recommendations by shop assistants or friends. To provide the most fitting recommendations they apply various filtering methods relying on data concerning the item, the user, or the artificial group a user is assigned to (Klahold, 2009). Recommender systems are very common in e-commerce and play an important role for increasing sales by reducing search costs and building e-trust (Pathak et al., 2010).
Scoring applications such as eBay’s reputation system gather and process feedback about participants’ behavior and derive ratings and scores relating to behavior from this (Resnick and Zeckhauser, 2002). A central purpose of these services is to build trust in an anonymous online environment and reduce transaction costs. Applications include sensitive areas such as credit scoring (Rothmann et al., 2014) or social scoring (measuring a person’s creditworthiness or social resources). Accordingly, these systems involve considerable risks of social discrimination on the grounds of a person’s race, age or religion and may infringe personal privacy (Bostic and Calem, 2003; Pavlov et al., 2004; Steinbrecher, 2006).
Furthermore, algorithms can be used to create content automatically, for example with applications such as Quill, developed by Narrative Science. These developments have recently been discussed under terms such as algorithmic, automated or robotic journalism (Levy, 2012; Steiner, 2012; Anderson, 2013; Dorr, 2015).
Automated production is not limited to text (e.g., tweets, news articles, business reports) but music production is affected as well. It allows for massive content production and contains the potential for the further rationalization and commercialization of media production. These applications touch deeply upon human areas of creativity and expression, leading to a revival of discussions about artificial intelligence software.Allocation applications independently and automatically conduct transactions (e.g., placement of ads) and allocate resources (Lee, 2007; Varian, 2009; Leinweber, 2009). Algorithmic trading software or computational advertising services such as Google AdSense are good examples of such applications. Computational advertising especially is the core revenue source for many online platforms such as search and social online networks (Evans, 2008).
19.3
More on the topic THE OPERATION MODEL AND FUNCTIONAL TYPOLOGY:
- THE OPERATION MODEL AND FUNCTIONAL TYPOLOGY
- A DEFINITION OF TRUST
- Three Classes of Models
- Theories and Models in Cognitive Science
- The functional aspect of the social organism
- A Baseline Model of Schumpeterian Growth
- Different Conceptions of Technology
- The Distinctive Role of Representations in Cognitive Science Explanations
- The Real Business Cycle Theory
- A Baseline Model of Schumpeterian Growth